PDF使用普通的复制黏贴到文本为乱码,使用Acrobat中的复制包含格式 到文本中可以。
对PDF进行一番后,认为这样应该是内嵌了字体,但是字体编码格式在我复制的时候无法解析或者类似的原因。
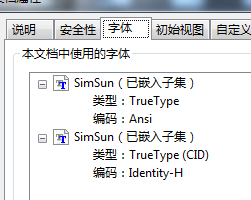
现在使用iTextSharp和PDFbox读取文本内容都是乱码。
http://www.thinksaas.cn/group/topic/327249/其中找到了一篇java版的PDFBox使用的解决方案。但是由于网上流传较多的是.7版本的PDFBox,高版本使用会出现错误,不会用。
现在想问一下,读取PDF文本乱码(不管是不是中文)的解决方案。





 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

