


65,212
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
int qx_tree_filter::filter(double*cost,double*cost_backup,int nr_plane)
{
memcpy(cost_backup,cost,sizeof(double)*m_h*m_w*nr_plane);
int*node_id=m_node_id;
int*node_idt=&(node_id[m_nr_pixel-1]);
for(int i=0;i<m_nr_pixel;i++)//for each pixel in image
{
int id=*node_idt--;
int id_=id*nr_plane;
int nr_child=m_mst_nr_child[id];
if(nr_child>0)
{
double*value_sum=&(cost_backup[id_]);
for(int j=0;j<nr_child;j++)
{
int id_child=m_mst_children[id][j];
int id_child_=id_child*nr_plane;
double weight=m_table[m_mst_weight[id_child]];
//value_sum+=m_mst_value_sum_aggregated_from_child_to_parent[id_child]*weight;
double*value_child=&(cost_backup[id_child_]);
for(int k=0;k<nr_plane;k++)
{
value_sum[k]+=(*value_child++)*weight;
}
}
}
//else
//{
// memcpy(&(cost_backup[id_]),&(cost[id_]),sizeof(double)*nr_plane);
//}
//printf("[id-value-weight]: [%d - %3.3f - %3.3f]\n",id,m_mst_[id].value_sum_aggregated_from_child_to_parent,m_mst_[id].weight_sum_aggregated_from_child_to_parent);
}
int*node_id0=node_id;
int tree_parent=*node_id0++;
int tree_parent_=tree_parent*nr_plane;
memcpy(&(cost[tree_parent_]),&(cost_backup[tree_parent_]),sizeof(double)*nr_plane);
for(int i=1;i<m_nr_pixel;i++)//K_00=f(0,00)[K_0-f(0,00)J_00]+J_00, K_00: new value, J_00: old value, K_0: new value of K_00's parent
{
int id=*node_id0++;
int id_=id*nr_plane;
int parent=m_mst_parent[id];
int parent_=parent*nr_plane;
double*value_parent=&(cost[parent_]);//K_0
double*value_current=&(cost_backup[id_]);//J_00
double*value_final=&(cost[id_]);
double weight=m_table[m_mst_weight[id]];//f(0,00)
for(int k=0;k<nr_plane;k++)
{
double vc=*value_current++;
*value_final++=weight*((*value_parent++)-weight*vc)+vc;///这句怎么搞?
}
//printf("Final: [id-value-weight]: [%d - %3.3f - %3.3f]\n",id,m_mst_[id].value_sum_aggregated_from_parent_to_child,m_mst_[id].weight_sum_aggregated_from_parent_to_child);
}
return(0);
}
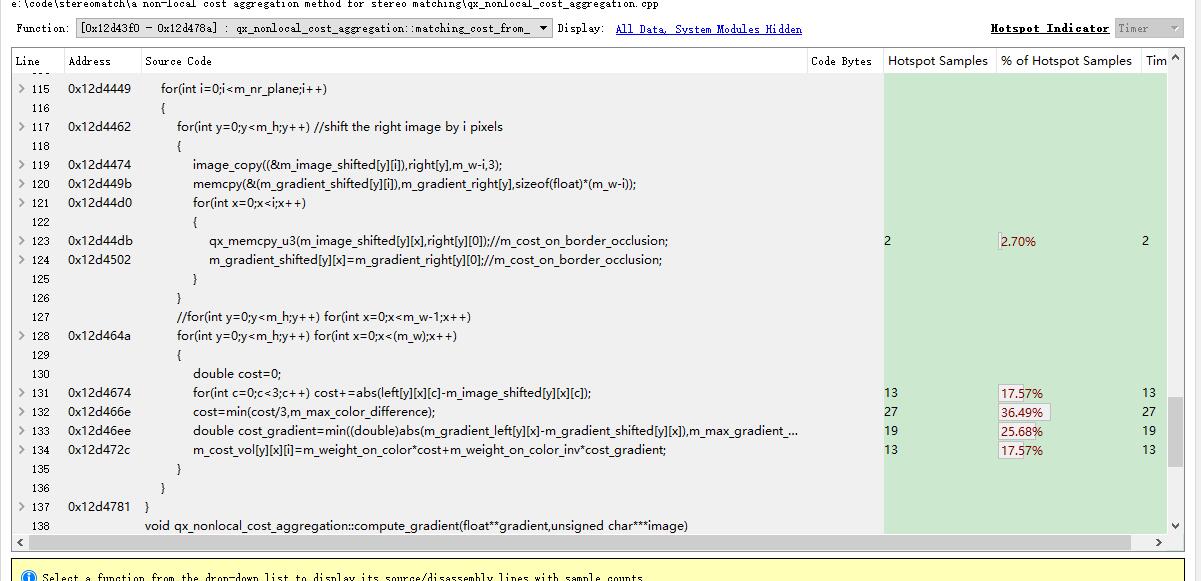
void qx_nonlocal_cost_aggregation::matching_cost_from_color_and_gradient(unsigned char ***left,unsigned char ***right)
{
image_zero(m_cost_vol,m_h,m_w,m_nr_plane);
compute_gradient(m_gradient_left,left);
compute_gradient(m_gradient_right,right);
for(int i=0;i<m_nr_plane;i++)
{
for(int y=0;y<m_h;y++) //shift the right image by i pixels
{
image_copy((&m_image_shifted[y][i]),right[y],m_w-i,3);
memcpy(&(m_gradient_shifted[y][i]),m_gradient_right[y],sizeof(float)*(m_w-i));
for(int x=0;x<i;x++)
{
qx_memcpy_u3(m_image_shifted[y][x],right[y][0]);//m_cost_on_border_occlusion;
m_gradient_shifted[y][x]=m_gradient_right[y][0];//m_cost_on_border_occlusion;
}
}
//for(int y=0;y<m_h;y++) for(int x=0;x<m_w-1;x++)
for(int y=0;y<m_h;y++) for(int x=0;x<(m_w);x++)
{
double cost=0;
for(int c=0;c<3;c++) cost+=abs(left[y][x][c]-m_image_shifted[y][x][c]);
cost=min(cost/3,m_max_color_difference);
double cost_gradient=min((double)abs(m_gradient_left[y][x]-m_gradient_shifted[y][x]),m_max_gradient_difference);
m_cost_vol[y][x][i]=m_weight_on_color*cost+m_weight_on_color_inv*cost_gradient;
}
}
}
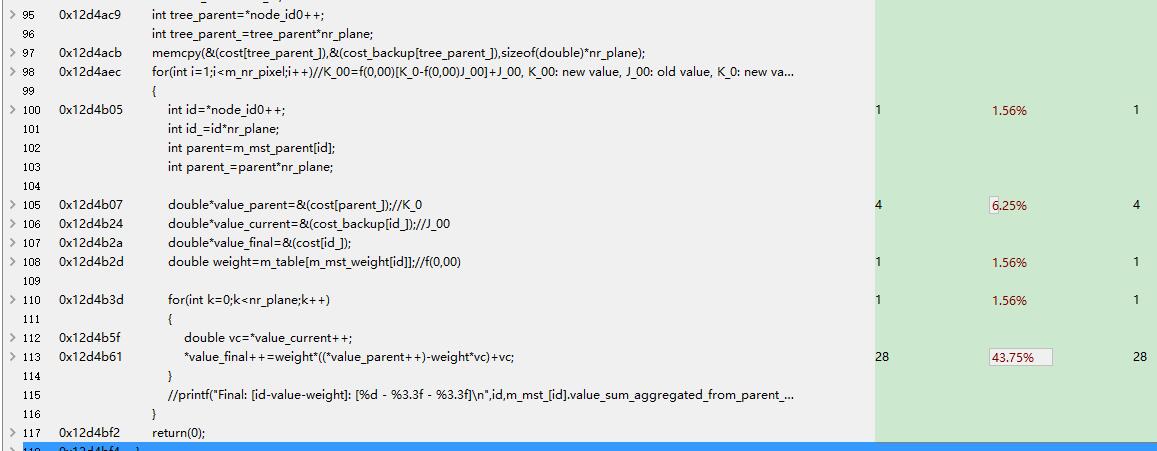


register double*value_parent=&(cost[parent_]);//K_0
register double*value_current=&(cost_backup[id_]);//J_00
register double*value_final=&(cost[id_]);
register double weight=m_table[m_mst_weight[id]];//f(0,00)
……
register double vc=*value_current++;
*value_final++=weight*((*value_parent++)-weight*vc)+vc;///这句怎么搞? 还真有!
还真有!






