


27,579
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


CREATE TABLE [dbo].[PN]
(
[PhoneNum] nvarchar(10),
[Num_Count_0] tinyint,
[Num_Count_1] tinyint,
[Num_Count_2] tinyint,
[Num_Count_3] tinyint,
[Num_Count_4] tinyint,
[Num_Count_5] tinyint,
[Num_Count_6] tinyint,
[Num_Count_7] tinyint,
[Num_Count_8] tinyint,
[Num_Count_9] tinyint
);
/*
受影响的行: 0
时间: 0.002s
*/
DECLARE @i BIGINT = 4000377888
WHILE @i <= 4005177888
BEGIN
INSERT INTO PN (PhoneNum) VALUES
(CAST(@i AS NVARCHAR(10))),
(CAST(@i+1 AS NVARCHAR(10))),
(CAST(@i+2 AS NVARCHAR(10))),
(CAST(@i+3 AS NVARCHAR(10))),
(CAST(@i+4 AS NVARCHAR(10))),
(CAST(@i+5 AS NVARCHAR(10))),
……
(CAST(@i+997 AS NVARCHAR(10))),
(CAST(@i+998 AS NVARCHAR(10))),
(CAST(@i+999 AS NVARCHAR(10)))
SET @i = @i + 1000
END;
/*
受影响的行: 1000
时间: 13.308s
*/
UPDATE PN SET
Num_Count_0 = LEN(PhoneNum) - LEN(REPLACE(PhoneNum, '0', '')),
Num_Count_1 = LEN(PhoneNum) - LEN(REPLACE(PhoneNum, '1', '')),
Num_Count_2 = LEN(PhoneNum) - LEN(REPLACE(PhoneNum, '2', '')),
Num_Count_3 = LEN(PhoneNum) - LEN(REPLACE(PhoneNum, '3', '')),
Num_Count_4 = LEN(PhoneNum) - LEN(REPLACE(PhoneNum, '4', '')),
Num_Count_5 = LEN(PhoneNum) - LEN(REPLACE(PhoneNum, '5', '')),
Num_Count_6 = LEN(PhoneNum) - LEN(REPLACE(PhoneNum, '6', '')),
Num_Count_7 = LEN(PhoneNum) - LEN(REPLACE(PhoneNum, '7', '')),
Num_Count_8 = LEN(PhoneNum) - LEN(REPLACE(PhoneNum, '8', '')),
Num_Count_9 = LEN(PhoneNum) - LEN(REPLACE(PhoneNum, '9', ''))
/*
受影响的行: 4801000
时间: 71.020s
*/
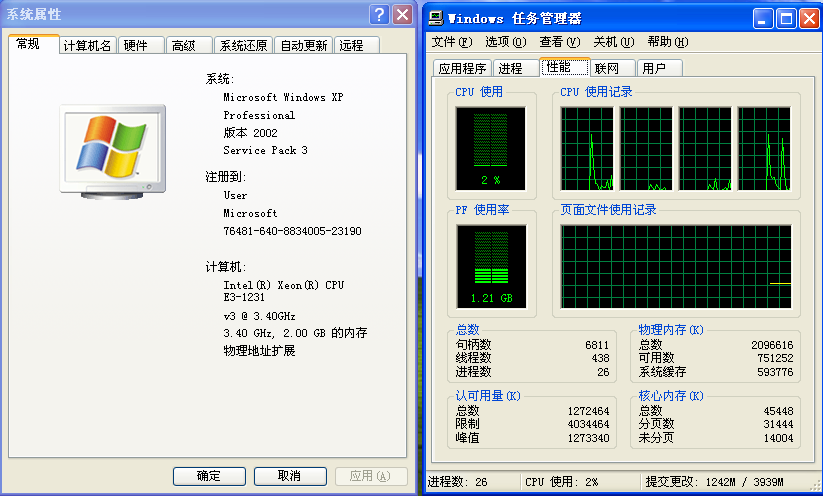
PRINT @@version
/*
Microsoft SQL Server 2008 R2 (RTM) - 10.50.1600.1 (Intel X86)
Apr 2 2010 15:53:02
Copyright (c) Microsoft Corporation
Express Edition on Windows NT 5.1 <X86> (Build 2600: Service Pack 3) (Hypervisor)
受影响的行: 0
时间: 0.007s
*/
SELECT PhoneNum FROM PN WHERE PhoneNum LIKE '%0377%'
/*
受影响的行: 0
时间: 5.277s
*/
SELECT SUM(1) FROM PN WHERE PhoneNum LIKE '%0377%'
/*
受影响的行: 0
时间: 4.607s
*/
SELECT PhoneNum FROM PN WHERE Num_Count_0 >= 1 AND Num_Count_3 >= 1 AND Num_Count_7 >= 2 AND PhoneNum LIKE '%0377%'
/*
受影响的行: 0
时间: 1.429s
*/
SELECT SUM(1) FROM PN WHERE Num_Count_0 >= 1 AND Num_Count_3 >= 1 AND Num_Count_7 >= 2 AND PhoneNum LIKE '%0377%'
/*
受影响的行: 0
时间: 0.740s
*/








 [/quote]
[/quote]
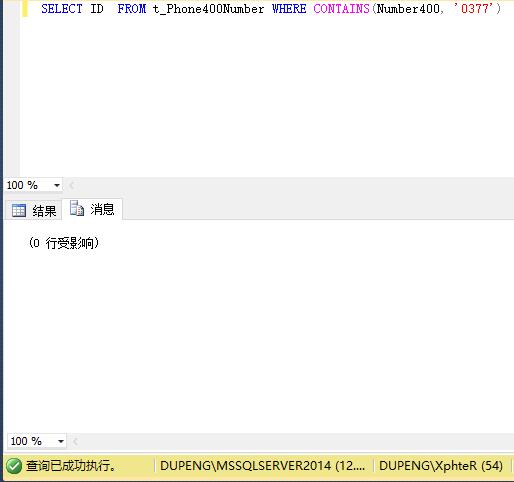
SELECT Number400 FROM tableName WHERE CONTAINS(Number400, '0377')
 [/quote]
你先分别执行下,
1. SELECT Number FROM tableName WHERE Number400 LIKE '%0377%'
2. SELECT Number FROM tableName WHERE CONTAINS(Number400, '0377')
看哪个快,如果一样的话说明导致速度变化的原因是执行select时候的阻塞。
如果上述成立,那你可以对列 Number400建立一个index,里面include进去你想要最后select出来的内容就行
[/quote]
你先分别执行下,
1. SELECT Number FROM tableName WHERE Number400 LIKE '%0377%'
2. SELECT Number FROM tableName WHERE CONTAINS(Number400, '0377')
看哪个快,如果一样的话说明导致速度变化的原因是执行select时候的阻塞。
如果上述成立,那你可以对列 Number400建立一个index,里面include进去你想要最后select出来的内容就行
SELECT * FROM tableName WHERE substring( Number400,4,4)= 0377
