很长时间没写过sql了,有个需求请大神帮忙写个sql。
有一张表:
CREATE TABLE `user_data` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`userid` bigint(20) NOT NULL COMMENT '用户ID',
`username` varchar(30) NOT NULL COMMENT '姓名',
`score` int(11) NOT NULL COMMENT '分数',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=utf8;
现插入数据
insert into user_data(userid,username,score) values(1,'小明',3);
insert into user_data(userid,username,score) values(1,'小明',4);
insert into user_data(userid,username,score) values(1,'小明',4);
insert into user_data(userid,username,score) values(1,'小明',5);
insert into user_data(userid,username,score) values(1,'小明',5);
insert into user_data(userid,username,score) values(1,'小明',5);
insert into user_data(userid,username,score) values(2,'小李',3);
insert into user_data(userid,username,score) values(2,'小李',4);
insert into user_data(userid,username,score) values(2,'小李',4);
insert into user_data(userid,username,score) values(2,'小李',8);
insert into user_data(userid,username,score) values(2,'小李',8);
insert into user_data(userid,username,score) values(2,'小李',5);
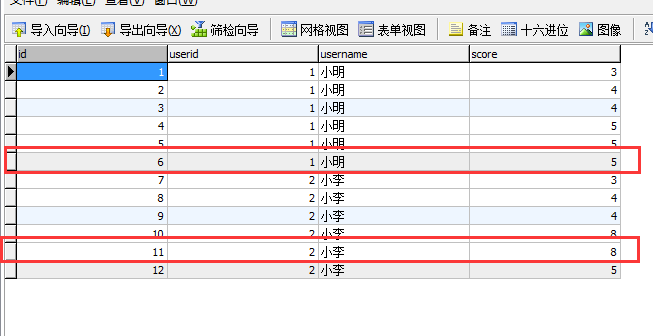
要求用一条sql取出所有人得分最多的那条记录如有相同得分的取自增ID最大的那条,意思就是一条sql的结果是



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



