Python 分词后去停止词,print输出无结果
用结巴分词后,想去停止词,用到以下方法:
①list(set(list1)-set(list2))
②for seg in seg_list :
if seg in stopword :
seg_list.remove(seg)
代码如下:
#!/usr/bin/python
#coding=utf-8
import jieba
import sys
import os
reload(sys)
sys.setdefaultencoding('utf-8')
print sys.getdefaultencoding()
print os.getcwd()
os.chdir("D:\\temp")
print os.getcwd()
data = open(r'title.txt')
result = open( "title2.txt" , "w+")
stop = open( r'chinese_stopword.txt')
a = stop.readlines()
b = [ ]
print a
for line in data.readlines() :
print line
seg_list = jieba.cut( line )
print ','.join(seg_list)
for elements in seg_list:
if elements not in a:
b.append(elements)
print "|".join(b)
aa = list(set(seg_list)-set(a))
print "|".join(aa)
print "运行结束"
data.close()
result.close()
stop.close()
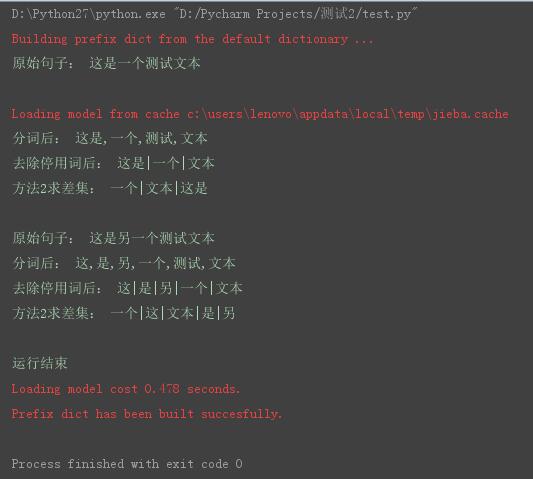
输出结果如下:
C:\Python27\python.exe D:/4,Python/Scripts/test/测试.py
utf-8
D:\4 Python\Scripts\test
D:\temp
['\xef\xbb\xbf\n', '\xe7\x9a\x84\n', '2016\n', '2015\n', '2017\n', '2009\n', '\xe5\xb9\xb4\n', '$\n', '0\n', '1\n', '2\n', '3\n', '4\n', '5\n', '6\n', '7\n', '8\n', '9\n', '?\n', '_\n', '\xe2\x80\x9c\n', '\xe2\x80\x9d\n', '\xe3\x80\x81\n', '\xe3\x80\x82\n', '\xe3\x80\x8a\n', '\xe3\x80\x8b\n', '\xe4\xb8\x80\n', '\xe7\x9a\x84\n', '\xe5\xb7\xb2\n', '\xe5\xae\x9e\xe7\x8e\xb0\n', '\xe5\xbe\x97\n', '\xe4\xba\x86\n', '\xe4\xb8\xaa\n', '\xe6\x9c\x88\n']
武汉土地流转打开融资门
,武汉,土地,流转,打开,融资,门,
扶绥扎实推进农村土地流转 已流转9.45万亩
扶绥,扎实,推进,农村土地,流转, ,已,流转,9.45,万亩,
问题
① 用自己赋值的简单list,这些方法都可以正常实现,但是在这个里面,都不能
② 求指出问题在哪里,我自己检查了文档,语法等,应该都没有问题,就是不晓得为什么不能输出
拜托大神指点!
a 的内容是:
的
2016
2015
2017
2009
年
$
0
1
2
3
4
5
6
7
8
9
?
_
“
”
、
。
《
》
一
的
已
实现
得
了
个
月



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享