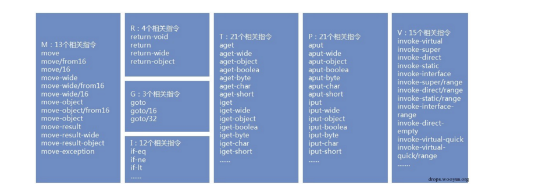
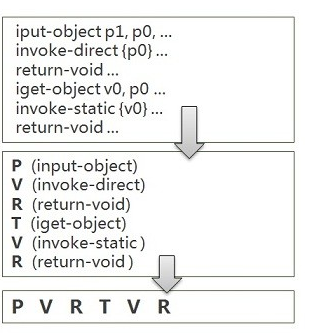
我给你总结一下吧,
读入某个文件,每一行里,如果匹配到了特定的字符串,就输出那个类别对应的字母。
(如果没有匹配到,就什么都不输出?)
所以有几个模式。
1 规则写在文件硬编码的条件语句里
f = open('input.txt')
for line in f:
if line.find('move') != -1:
print 'M '
elif line.find('move/16 ') != -1:
print 'M '
...
close(f)
2 预先把规则处理成对照表,然后把对照表读到数组中
对照表 rule.csv
move, M
move/16, M
...
r = open('rule.csv')
rules = {}
lines = r.readlines()
r.close()
for line in lines:
pair = line.split(',')
rules.append(pair)
f = open('input.txt')
for line in f:
for rule in rules:
if line.find(rule[0]) != -1:
print rule[1]
close(f)
不太明白你想说什么,猜是不是这样
import os,sys
file_destiny = open("destiny.txt","w")
file_source = open("data.txt","r")
words = file_source.readlines()
bb = ".".join(words).split(" ")
n= 0
aa = ["move","move16","move wide"]
for word in bb:
if word in aa:
file_destiny.write(word + "\n")
n = n+1
print(n)
file_destiny.close()
file_source.close()



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享