



22,210
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享with t(id,Result) as
(
select 1,'2.2' union all
select 2,'3.3' union all
select 3,'2...2'
)
select * into #A from t;
select * from #A where cast(Result as decimal(18,5))>3 and id in(1,2) --谓词里:先执行cast(Result as decimal(18,5))>3,后执行id in(1,2)。报错
select * from #A where id in(1,2) and cast(Result as decimal(18,5))>3 --因为,in等级靠后,即使写前面,谓词里也会排后面,顺序同上。报错
select * from #A where cast(Result as decimal(18,5))>3 and id <=2 --">" 与 "<="同级,但有函数的等级估计比没函数的等级低,估计不报错
select * from #A where id <=2 and cast(Result as decimal(18,5))>3 --百分百不报错
;with t(id,Result) as
(
select 1,'2.2' union all
select 2,'3.3' union all
select 3,'2...2'
)
select * from t where id =2 and cast(Result as decimal(18,5))>3 --都等号了,优化器还把它的谓词顺序调到后面,这是为啥?






-- Create table
create table TEST_ARAY
(
a NUMBER(1),
b VARCHAR2(10)
);
-- Create/Recreate indexes
create bitmap index IDX_A on TEST_ARAY (A);
create index IDX_B on TEST_ARAY (B);

with t(id,Result) as
(
select 1,'2.2' union all
select 2,'3.3' union all
select 3,'2...2'
)
select * from t where id =2 and cast(Result as decimal(18,5))>3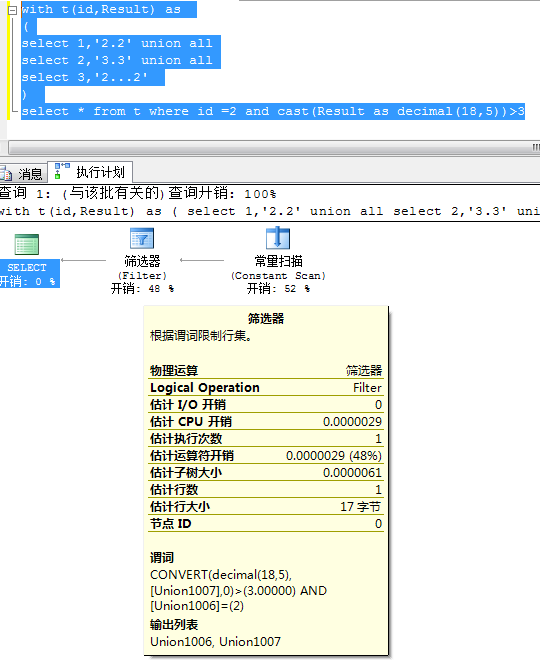

with t(id,Result) as
(
select 1,'2.2' union all
select 2,'3.3' union all
select 3,'2...2'
)
select * into #a from t
select * from #a where id =2 and cast(Result as decimal(18,5))>3 with t(id,Result) as
(
select 1,'2.2' union all
select 2,'3.3' union all
select 3,'2...2'
)
select * into #A from t;
--1.
SELECT * from #A where id*1 <=2 and cast(Result as decimal(18,5))>3
--2.
select * from #A where CAST(id AS INT) <=2 and cast(Result as decimal(9,5))>3
--3.
select * from #A where CAST(id AS DECIMAL(9,5)) <=2 and cast(Result as decimal(9,5))>3
--4.
select * from #A WHERE CAST(Result as decimal(9,5))>3 AND CAST(id AS DECIMAL(9,5)) <=2
谓词里,靠后的条件,只会遍历靠前的条件筛选出的结果集,而不会遍历全表了如何优化,才能上谓词的顺序,随我的要求变化1.Equal谓词2.Range谓词3.In列表4.Like谓词 。从没有过这个思路,但这信些出去,是否还要英文啊,中文描述问题都挺困难,英文更描述不清了。另外,哪个邮箱能收这种信啊?
。从没有过这个思路,但这信些出去,是否还要英文啊,中文描述问题都挺困难,英文更描述不清了。另外,哪个邮箱能收这种信啊?




