



22,207
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享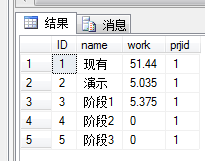





-- 看看你要哪个结果
print '--分组的'
SELECT prjid,现有,演示,阶段1,阶段2,阶段3
from
(select prjid,name, work FROM test ) p
pivot(
max(work)
for
name
IN (现有,演示,阶段1,阶段2,阶段3)
) as a
go
print '--不分组的'
SELECT prjid,现有,演示,阶段1,阶段2,阶段3
from test
pivot(
max(work)
for
name
IN (现有,演示,阶段1,阶段2,阶段3)
) as a
go

with PhaseWork(id,name,work,prjid) as
(
select 1,'现有',51.44,1 union all
select 2,'演示',5.035,1 union all
select 3,'阶段1',5.375,1 union all
select 4,'阶段2',0,1 union all
select 5,'阶段3',0,1
)
select * from PhaseWork pivot( max(work) for name in ([现有],[演示],[阶段1],[阶段2],[阶段3])) as b
/*
1 1 51.440 NULL NULL NULL NULL
2 1 NULL 5.035 NULL NULL NULL
3 1 NULL NULL 5.375 NULL NULL
4 1 NULL NULL NULL 0.000 NULL
5 1 NULL NULL NULL NULL 0.000
*/use Tempdb
go
--> -->
declare @PhaseWork table([ID] int,[name] nvarchar(23), [work] DECIMAL(18,9), prjid int)
Insert @PhaseWork
select 1,N'现有',51.44,1 union all
select 2,N'演示',5.035,1 union all
select 3,N'阶段1',5.375,1 union all
select 4,N'阶段2',0,1 union all
select 5,N'阶段3',0,1
SELECT * FROM (SELECT [name],[work],[prjid] from @PhaseWork ) AS a
pivot(
MAX(work)
for
[name]
IN (现有,演示,阶段1,阶段2,阶段3)
) as b
/*
prjid 现有 演示 阶段1 阶段2 阶段3
1 51.440000000 5.035000000 5.375000000 0.000000000 0.000000000
*/


