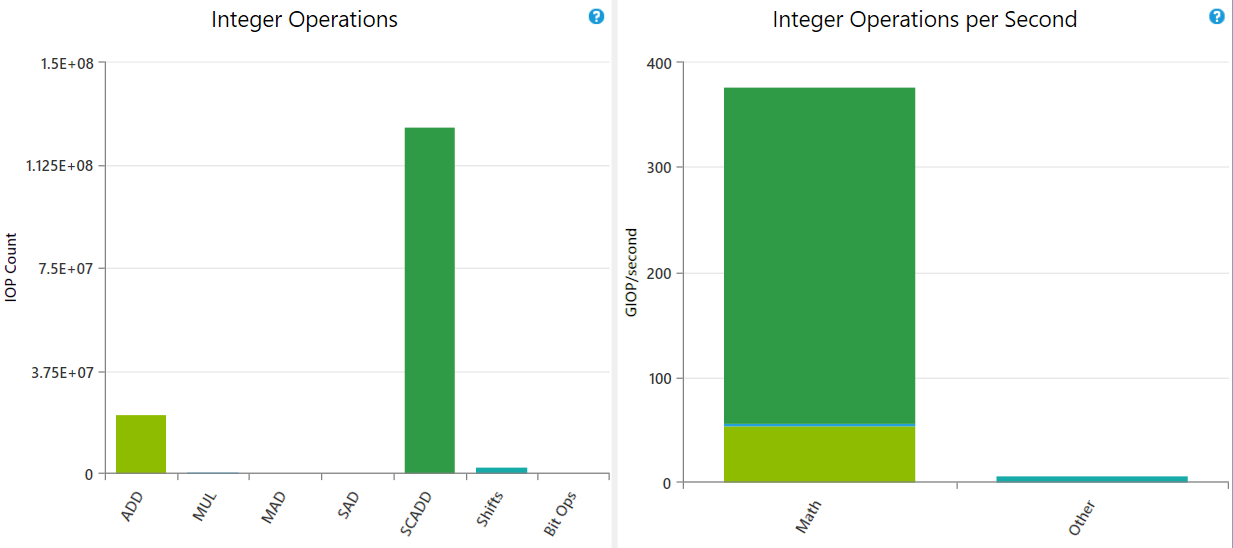
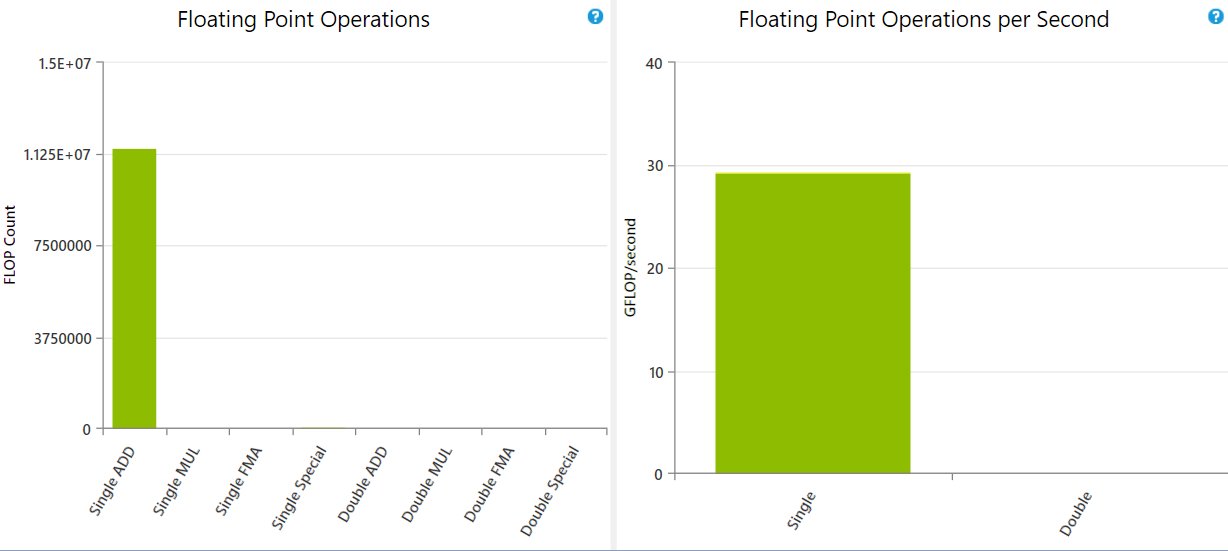
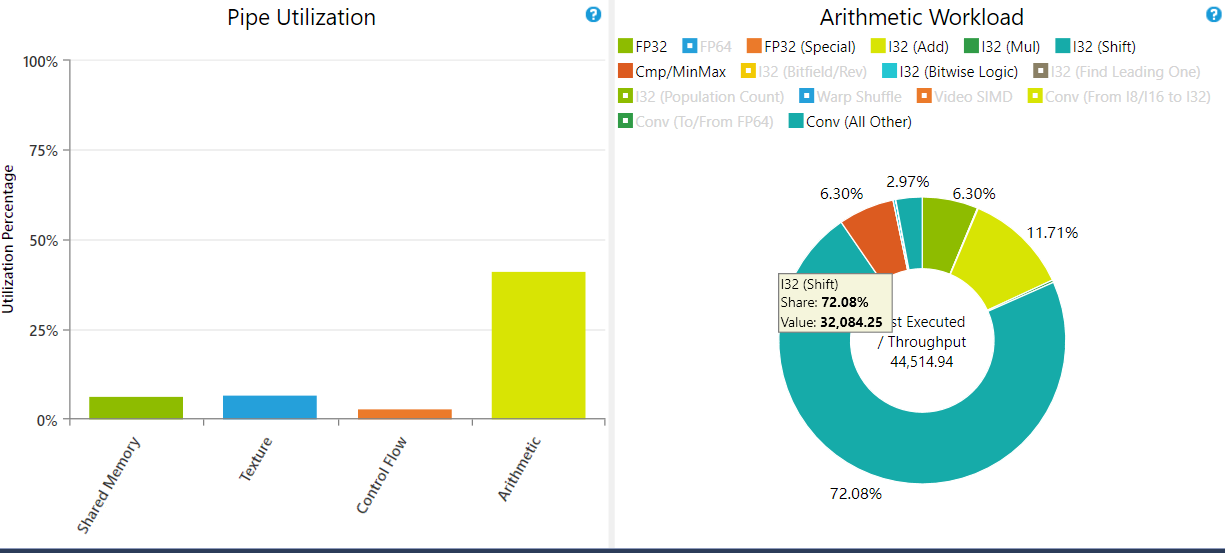
核函数如下,感觉在for循环里没有用到多少I32运算,为什么scadd出来这么高
#define win_N 24
#define inf 100
#define win_L 100
#define info_L 2400
#define info_tL 2403
#define block_N 88
#define ab_thread_N 384
#define info_thread_N 800
#define half_abt_N 192
__global__ void ab3Kernel(float *dev_gamma, float *dev_ab, float *last_alfa, float *last_beta, int *dev_para, int iteration) //last iteration value
{
__shared__ float shr_alfa[half_abt_N];
__shared__ float shr_beta[half_abt_N];
__shared__ float shr_illr[ab_thread_N];
__shared__ float shr_jllr[ab_thread_N];
float plus, minus, gamma;
// unsigned int ab_judge = threadIdx.x / half_abt_N;
unsigned int win_n = threadIdx.x%half_abt_N >> 3;
unsigned int state_n = threadIdx.x & 7;
unsigned int tmp_base = win_n << 3;
unsigned int tmp_idx = tmp_base + state_n;
//unsigned int v_train = 3; //set to be even ,in case we know whether shr_ab0 or shr_ab1 get train result
unsigned int i;
float *g_loc, *add_loc, *sub_loc, *non_loc,*ab_idx;
//__shared__ int g_tab[8];// = { 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 1 };
//__shared__ int add_tab[8];// = { 1, 2, 5, 6, 0, 3, 4, 7, 4, 0, 1, 5, 6, 2, 3, 7 };
//__shared__ int sub_tab[8];// = { 0, 3, 4, 7, 1, 2, 5, 6, 0, 4, 5, 1, 2, 6, 7, 3 };
if (threadIdx.x < half_abt_N)
{
/*get parameter from mem*/
ab_idx = dev_ab + ((blockIdx.x*info_L + win_n*win_L) * 8 + state_n);
g_loc = dev_gamma + ((blockIdx.x*info_tL + win_n*win_L) * 2 + dev_para[state_n]);
add_loc = shr_alfa + (tmp_base + dev_para[16 + state_n]);
sub_loc = shr_alfa + (tmp_base + dev_para[32 + state_n]);
non_loc = shr_alfa+tmp_idx;
/*get last alfa*/
if (iteration == 0)
{
*non_loc = state_n == 0 ? 0.0f : -100.0f;
if (win_n > 0)
{
for (i = 2 * 20; i >0; i -= 2)
{
gamma = *(g_loc - i);
plus = *add_loc + gamma;
minus = *sub_loc - gamma;
*non_loc = fmaxf(plus, minus);
}
}
}
else
{
*non_loc = last_alfa[blockIdx.x*win_N * 8 + tmp_idx];
}
/*calculate half alfa*/
for (i = 0; i < (win_L>>1); i ++)
{
*ab_idx = *non_loc;
gamma = *g_loc;
plus = *add_loc + gamma;
minus = *sub_loc - gamma;
*non_loc = fmaxf(plus, minus);
ab_idx = ab_idx + 8;
g_loc = g_loc + 2;
}
}
else
{
/*get parameter from mem*/
ab_idx = dev_ab + ((blockIdx.x*info_L + win_n*win_L) * 8 + state_n + (win_L - 1) * 8);
g_loc = dev_gamma + ((blockIdx.x*info_tL + win_n*win_L) * 2 + dev_para[8 + state_n] + 2 * (win_L - 1));
add_loc = shr_beta + (tmp_base + dev_para[24 + state_n]);
sub_loc = shr_beta + (tmp_base + dev_para[40 + state_n]);
non_loc = shr_beta+tmp_idx;
/*get last beta*/
if (iteration == 0)
{
int v_L = win_n == win_N - 1 ? 3 : 20;
*non_loc = state_n == 0 ? 0.0f : -100.0f;
for (i = 2 * v_L; i >0 ; i -= 2)
{
gamma = *(g_loc + i);
plus = *add_loc + gamma;
minus = *sub_loc - gamma;
*non_loc = fmaxf(plus, minus);
}
if (win_n == win_N - 1)
{
last_beta[blockIdx.x*win_N * 8 + tmp_idx] = *non_loc;
}
}
else
{
*non_loc = last_beta[blockIdx.x*win_N * 8 + tmp_idx];
}
/*calculate half beta*/
for(i = 0; i < (win_L >> 1); i++)
{
*ab_idx = *non_loc;
gamma = *g_loc;
plus = *add_loc + gamma;
minus = *sub_loc - gamma;
*non_loc = fmaxf(plus, minus);
ab_idx = ab_idx - 8;
g_loc = g_loc - 2;
}
}
__syncthreads();
/*calculate rest alfa\beta and prepare for llr*/
if (threadIdx.x < half_abt_N)
{
float *d_tmp_idx0 = shr_illr+2 * tmp_idx;
float *d_tmp_idx1 = shr_illr + (2 * tmp_idx + 1);
float *low_idx = shr_illr + (tmp_base + tmp_idx);
float *high_idx = shr_illr + (tmp_base + tmp_idx + 8);
for (; i < win_L; i ++)
{
gamma = *g_loc;
plus = *add_loc + gamma;
minus = *sub_loc - gamma;
*non_loc = fmaxf(plus, minus);
*low_idx = *ab_idx + minus;
*high_idx = *ab_idx + plus;
*ab_idx = fmaxf(*d_tmp_idx0, *d_tmp_idx1);
ab_idx = ab_idx + 8;
g_loc = g_loc + 2;
}
if (win_n < win_N - 1)
{
last_alfa[blockIdx.x*win_N * 8 + tmp_idx + 8] = *non_loc;
}
}
else
{
float *d_tmp_idx0 = shr_jllr + 2 * tmp_idx;
float *d_tmp_idx1 = shr_jllr + (2 * tmp_idx + 1);
float *low_idx = shr_jllr + (tmp_base + tmp_idx);
float *high_idx = shr_jllr + (tmp_base + tmp_idx + 8);
for (; i < win_L; i++)
{
gamma = *g_loc;
plus = *add_loc + gamma;
minus = *sub_loc - gamma;
*non_loc = fmaxf(plus, minus);
*low_idx = *ab_idx + minus;
*high_idx = *ab_idx + plus;
*ab_idx = fmaxf(*d_tmp_idx0, *d_tmp_idx1);
ab_idx = ab_idx - 8;
g_loc = g_loc - 2;
}
if (win_n > 0)
{
last_beta[blockIdx.x*win_N * 8 + tmp_idx - 8] = *non_loc;
}
}
}




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
