

111,129
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

 [/quote]
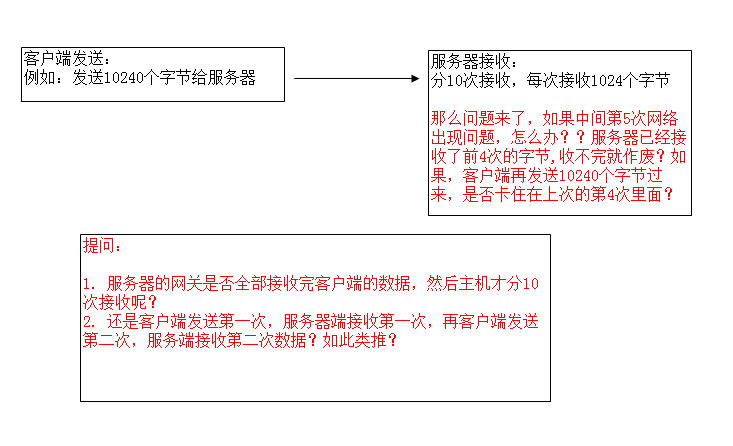
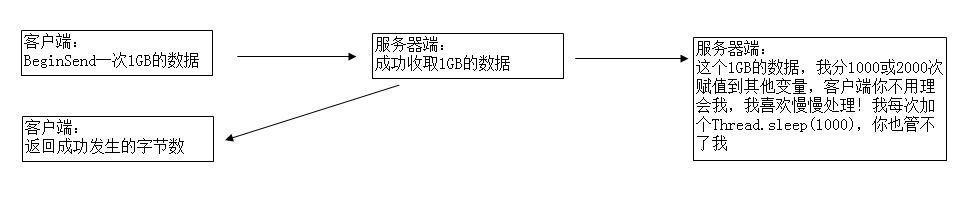
send/beginsend的返回值表示发送成功的字节数,这个字节数表示发送到本地socket的发送缓存中成功了,并不代表接收端已经成功收到了。
服务端的recv中断与否取决于你怎么编写接收代码,recv/beginrecv仅仅是从socket接收缓存中提取数据而已,有数据来了就会被取出来,例如,客户端一次send了10000,实际过程分为1000+5000+4000到达服务端,那么服务端的recv/beginrecv会返回三次来接收这10000个字节,而不是一直等着10000各字节全部达到再一次性返回。
[/quote]
send/beginsend的返回值表示发送成功的字节数,这个字节数表示发送到本地socket的发送缓存中成功了,并不代表接收端已经成功收到了。
服务端的recv中断与否取决于你怎么编写接收代码,recv/beginrecv仅仅是从socket接收缓存中提取数据而已,有数据来了就会被取出来,例如,客户端一次send了10000,实际过程分为1000+5000+4000到达服务端,那么服务端的recv/beginrecv会返回三次来接收这10000个字节,而不是一直等着10000各字节全部达到再一次性返回。


client.Send(retDatas);ThreadPool.QueueUserWorkItem(h => 判断处理程序并调用程序(msg, client));scr.Send(mydatas);

