37,744
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
# -*- coding: utf-8 -*-
from __future__ import print_function
import numpy as np
from time import time
from sklearn.datasets import load_svmlight_file
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.cross_validation import train_test_split
#from sklearn.metrics import classification_report
from sklearn import metrics
from sklearn.pipeline import Pipeline
from sklearn.externals import joblib
from sklearn.grid_search import GridSearchCV
import pandas as pd
def get_data(fname):
content = pd.read_excel(fname, encoding='csc')
label = content['label']
del content ['label']
feature = pd.DataFrame(content)
return feature, label
#文件读取与切割
print("Loading data")
t0 = time()
filename = "F:\\textdata\\sample.20160628(labelled).xlsx"
X0,y0 = get_data(filename)
X = X0.values
y = y0.values
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3,random_state=42)
t1 = time()
print("Loading completed, costing %0.3fs" % (t1-t0))
#搭建RandomForest模型
#X_single = X_test[0:1]
clf = RandomForestClassifier(n_estimators = 100)
print("Data Fitting START")
t0 = time()
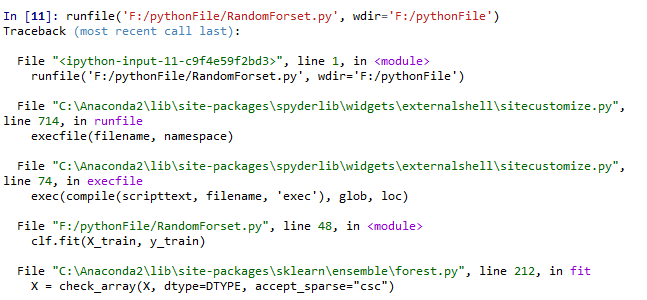
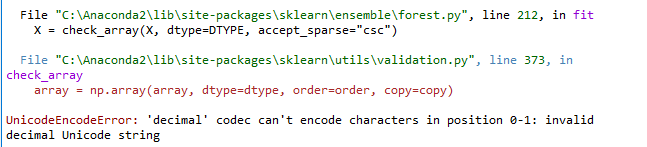
clf.fit(X_train, y_train)
t1 = time()
print("Fitting completed, costing %0.3fs" % (t1-t0))
#模型测试
print("Model testing START")
t0 = time()
pred = clf.predict(X_test)
t1 = time()
print("Testing completed, costing %0.3fs" % (t1-t0))
#模型评估
accuracy = metrics.accuracy_score(y_test, pred)
print("accuracy_score: %f" % accuracy)
recall = metrics.recall_score(y_test, pred)
print("recall_score: %f" % recall)
print(metrics.classification_report(y_test, pred))