

37,739
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享 identity = driver.find_elements_by_xpath("//a[@class='W_texta W_fb']")

 这帮不了你了试试identity[1],identity[2]之类的,看官方API[/quote]
这帮不了你了试试identity[1],identity[2]之类的,看官方API[/quote]
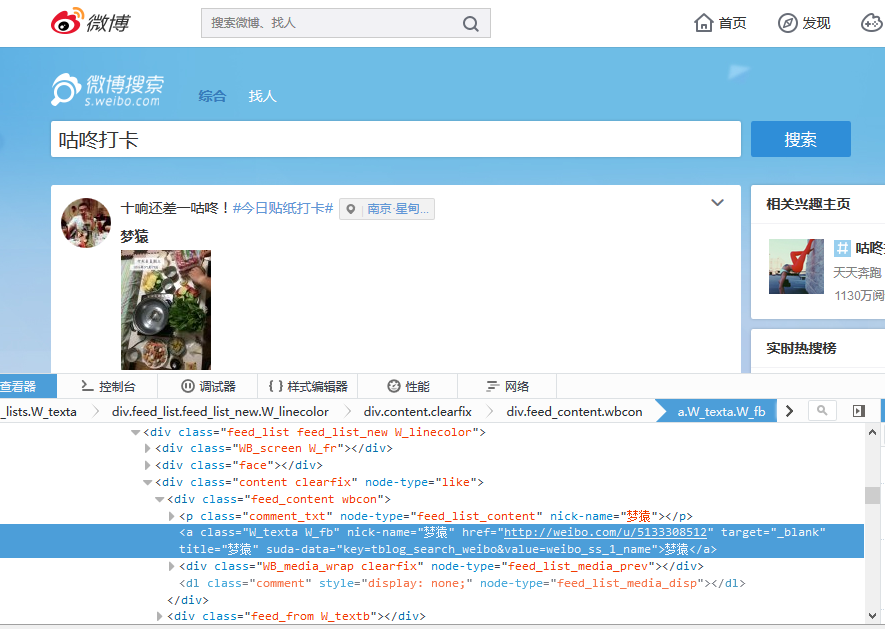 根据[code=pythonidentity = driver.find_elements_by_xpath("//a[@class='W_texta W_fb']")][/code]这个类,我可以把后面的href,也就是http://weibo.com/u/5133308512拿出来吗?
这帮不了你了试试identity[1],identity[2]之类的,看官方API[/quote]
这个identity是driver.find_elements_by_xpath("//a[@class='W_texta W_fb']"),从微博来看,它包含图片里面的内容,可是我要怎样才能提取出来呢?
[/quote]
什么意思?identity[0].text 你还不知道是什么内容?[/quote]
显示的是nick-name的内容,identity打印出来是空的[/quote]
这帮不了你了试试identity[1],identity[2]之类的,看官方API[/quote]
identity显示是个list,identity打印出来是空的
根据[code=pythonidentity = driver.find_elements_by_xpath("//a[@class='W_texta W_fb']")][/code]这个类,我可以把后面的href,也就是http://weibo.com/u/5133308512拿出来吗?
这帮不了你了试试identity[1],identity[2]之类的,看官方API[/quote]
这个identity是driver.find_elements_by_xpath("//a[@class='W_texta W_fb']"),从微博来看,它包含图片里面的内容,可是我要怎样才能提取出来呢?
[/quote]
什么意思?identity[0].text 你还不知道是什么内容?[/quote]
显示的是nick-name的内容,identity打印出来是空的[/quote]
这帮不了你了试试identity[1],identity[2]之类的,看官方API[/quote]
identity显示是个list,identity打印出来是空的
 这帮不了你了试试identity[1],identity[2]之类的,看官方API
这帮不了你了试试identity[1],identity[2]之类的,看官方API identity = driver.find_elements_by_xpath("//a[@class='W_texta W_fb']")
pattern = re.compile("http://weibo.com/(.*?)\?")
items = re.findall(pattern, identity[0].text)
print items
import re
string = "aaaaaaaaaaahttp://weibo.com/abcde?bbbbbbbbbbbbbb"
pattern = re.compile("http://weibo.com/(.*?)\?")
items = re.findall(pattern, string)
print(items)

