[quote=引用 1 楼 qq646222123 的回复:] 你的具体需求虽然我不知道,但是一般循环套循环 , 循环内还要数据操作的 , 数据量小了到看不出来什么来 , 数据量大了就不行 , 一个请求需要双层迭代 , 单线程内存开销很大 , 如果这种编写方式无法替换的话 建议用多线程去实现 , 即第一层for的 每个l 放进一个线程 , 把下面的逻辑 写进 继承Thread类或者 实现Runnable接口 的自定义类里面 , 这样就相当于 多个线程同时 处理 你最外层 list 的每个元素 , 还有你下面 executeDb的方法 里面是怎么写的 有没有分批处理
你的具体需求虽然我不知道,但是一般循环套循环 , 循环内还要数据操作的 , 数据量小了到看不出来什么来 , 数据量大了就不行 , 一个请求需要双层迭代 , 单线程内存开销很大 , 如果这种编写方式无法替换的话 建议用多线程去实现 , 即第一层for的 每个l 放进一个线程 , 把下面的逻辑 写进 继承Thread类或者 实现Runnable接口 的自定义类里面 , 这样就相当于 多个线程同时 处理 你最外层 list 的每个元素 , 还有你下面 executeDb的方法 里面是怎么写的 有没有分批处理
81,114
社区成员
341,727
社区内容
加载中
试试用AI创作助手写篇文章吧


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享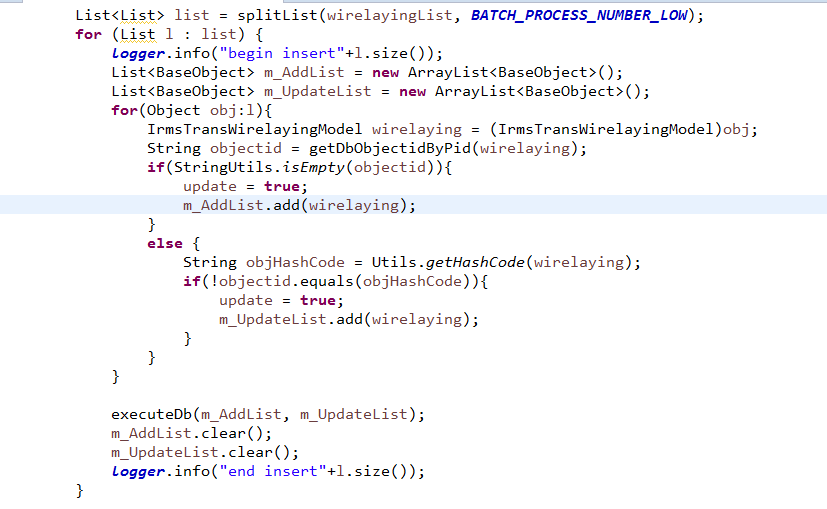




 你说的好有道理,这是怎个过程,请看看有没有问题呢
明天我再试试你说的多线程。[/quote]
你实行sql的这里 哪里是分批 啊 虽然你用了 addBatch 但是 你又把整个 list中的数据全部 添加到 Batch里面 把整个 Batch提交了这不又相当于 并没有 分批 你可以网上搜一下 JDBC 分批次 提交的代码写法 有很多
你说的好有道理,这是怎个过程,请看看有没有问题呢
明天我再试试你说的多线程。[/quote]
你实行sql的这里 哪里是分批 啊 虽然你用了 addBatch 但是 你又把整个 list中的数据全部 添加到 Batch里面 把整个 Batch提交了这不又相当于 并没有 分批 你可以网上搜一下 JDBC 分批次 提交的代码写法 有很多


