



37,720
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
import re
html = '''<a href="/en/UID=0000">C</a>
<ul class="tree">
<li class="tree"><a href="/en/UID=1111">CHENi</a></li>
<li class="tree"><a href="/en/UID=3333">HUANG</a></li>
<li class="tree"><a href="/en/UID=2222">Zhang</a></li>
</ul>'''
ptn = re.compile(r'<li[^>]*?class="tree".*?'
r'href="/en/UID=([^"]*)">'
r'([^<]*).*?</li>'
,re.S)
mch = ptn.findall(html)
print(mch)
[('1111', 'CHENi'), ('3333', 'HUANG'), ('2222', 'Zhang')]
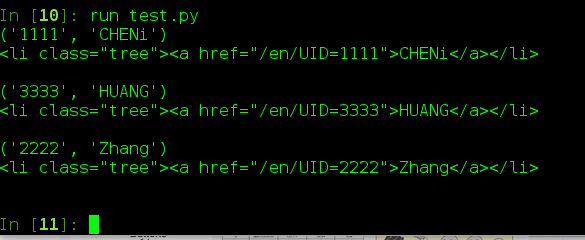
#!/usr/bin/python
# -*- coding:utf-8 -*-
import re
f1 = open('t1.txt','r').readlines()
i=0
p1 = re.compile(r'<li class="tree"><a href="/en/UID=(\d{4})">(\w+)</a></li>')
for line in f1:
res = p1.search(line)
if(res):
print res.groups()
print line
# print i,line
#print f1

