社区
C#
帖子详情
C#读取大TXT导入ORACLE,并查询和原始表的重复数据。
bntiger
2016-09-16 02:40:42
现在有个千万级数据库,每天都要导入每个TXT 100万条记录,想实现在导入前想判断是否有重复,没有重复才可以批量插入。
我目前利用OracleBulkCopy,可以实现批量的导入。关于重复判断,导入前,如果直接好用数据DATATABLE循环select原始表对比,速度非常的慢;也曾想利用临时表,然后用INTERSECT查询两个表的交集,如果有就说明有重复。但这些办法效率很低。
所以很特提出优化方案,请指正。
...全文
210
4
打赏
收藏
C#读取大TXT导入ORACLE,并查询和原始表的重复数据。
现在有个千万级数据库,每天都要导入每个TXT 100万条记录,想实现在导入前想判断是否有重复,没有重复才可以批量插入。 我目前利用OracleBulkCopy,可以实现批量的导入。关于重复判断,导入前,如果直接好用数据DATATABLE循环select原始表对比,速度非常的慢;也曾想利用临时表,然后用INTERSECT查询两个表的交集,如果有就说明有重复。但这些办法效率很低。 所以很特提出优化方案,请指正。
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
4 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
hiose89
2016-09-16
打赏
举报
回复
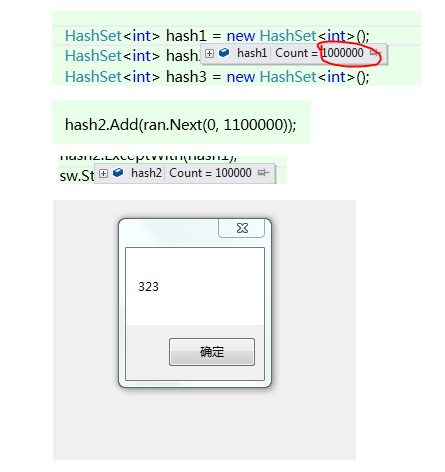
帮你试了一下 用hashset 算110 万和100万之间 的重复数 只用了300多毫秒。
而且我的是渣渣笔记本。
hiose89
2016-09-16
打赏
举报
回复
真巧啊 ,我正好做了个视频 有讲到大数据不重复 对比。
不过视频很长,有兴趣你可以看看
http://v.youku.com/v_show/id_XMTcyNzU2MjEyOA==.html
shoppo0505
2016-09-16
打赏
举报
回复
先把全部数据导入数据库的另外一个表,判断重复再数据库层面做
800字以内
2016-09-16
打赏
举报
回复
hash 方面可以想办法提速吧? 没接触过 帮顶
vc++ 应用源码包_1
如题,此实例非常适合学习,重载并自绘了Wnd类,效果是上下文字、图片、文字由大到小和星星闪烁等滚动效果。实例使用了加载类似xml文件
读取
信息,然后显示。 COM_ATL_Tutorial 简单的atl控件演示 COM接口挂钩及其...
vc++ 应用源码包_2
如题,此实例非常适合学习,重载并自绘了Wnd类,效果是上下文字、图片、文字由大到小和星星闪烁等滚动效果。实例使用了加载类似xml文件
读取
信息,然后显示。 COM_ATL_Tutorial 简单的atl控件演示 COM接口挂钩及其...
C#
零基础入门课程
C#
基础语法:详细讲解
C#
的基本语法规则和代码结构,包括变量和
数据
类型的声明和使用、运算符的种类和应用、控制语句的编写等。 面向对象编程:深入介绍面向对象编程的基本概念,如类、对象、继承、多态、封装和抽象...
vc++ 应用源码包_6
如题,此实例非常适合学习,重载并自绘了Wnd类,效果是上下文字、图片、文字由大到小和星星闪烁等滚动效果。实例使用了加载类似xml文件
读取
信息,然后显示。 COM_ATL_Tutorial 简单的atl控件演示 COM接口挂钩及其...
vc++ 应用源码包_5
如题,此实例非常适合学习,重载并自绘了Wnd类,效果是上下文字、图片、文字由大到小和星星闪烁等滚动效果。实例使用了加载类似xml文件
读取
信息,然后显示。 COM_ATL_Tutorial 简单的atl控件演示 COM接口挂钩及其...
C#
110,536
社区成员
642,578
社区内容
发帖
与我相关
我的任务
C#
.NET技术 C#
复制链接
扫一扫
分享
社区描述
.NET技术 C#
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
让您成为最强悍的C#开发者
试试用AI创作助手写篇文章吧
+ 用AI写文章




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享