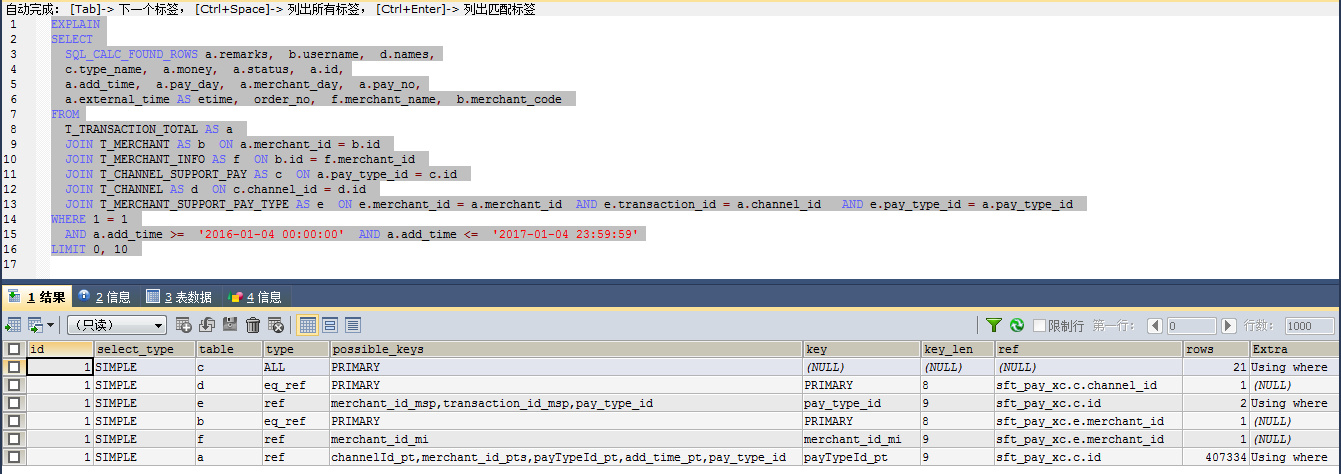
mysql表数据量超过1千万时,批量更新相当慢,查询也慢
 孤单大眼鱼 2016-09-18 02:31:44
孤单大眼鱼 2016-09-18 02:31:44 ld_bus_code_list 码值总表
ld_bus_code_management 编码管理表
页面点击分配码值会在编码管理表生成一条记录,并把对应的id更新到码值总表
之前是没问题的,但是ld_bus_code_list这张表的数据量超过1千万就卡死了,
更新语句如下
update ld_bus_code_list set cm_id = 22 where cm_id is null limit 1000000;
大神们帮忙分析一下原因,cm_id 有加索引


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享