

111,132
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享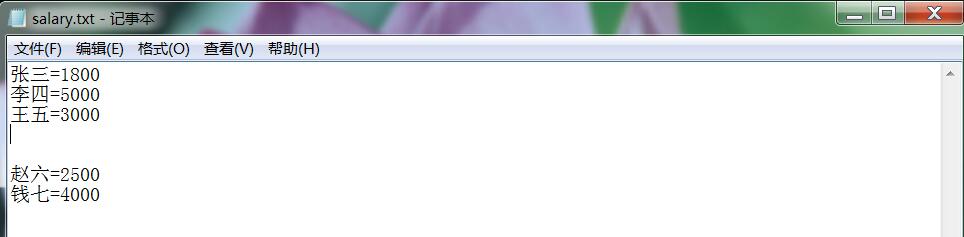
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace Test_160916_003
{
class Program
{
static void Main(string[] args)
{
string[] lines = File.ReadAllLines("salary.txt", Encoding.Default);
//假设第一个人的工资即为最高工资,也为最低工资。
double max = double.Parse( lines[0].Split('=')[1] );
double min = double.Parse(lines[0].Split('=')[1]);
double sum = 0;
double count = 0;
for (int i = 0; i < lines.Length; i++)
{
if (lines.Length != 0)
{
count++;
double money = double.Parse(lines[i].Split('=')[1]);
sum += money;
if (max < money)
{
max = money;
}
if (min > money)
{
min = money;
}
} //if(lines[i].Length != 0)
}
Console.WriteLine("最高工资为{0}", max);
Console.WriteLine("最低工资为{0}", min);
Console.WriteLine("平均工资为{0}", (sum / count) );
Console.ReadKey();
}
}
}
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace Test_160916_003
{
class Program
{
static void Main(string[] args)
{
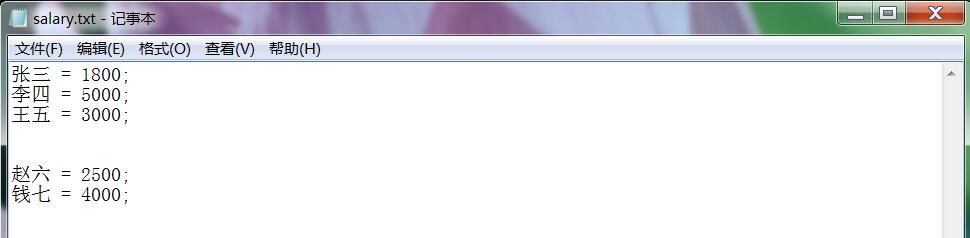
string[] lines = File.ReadAllLines("salary.txt", Encoding.Default);
//假设第一个人的工资即为最高工资,也为最低工资。
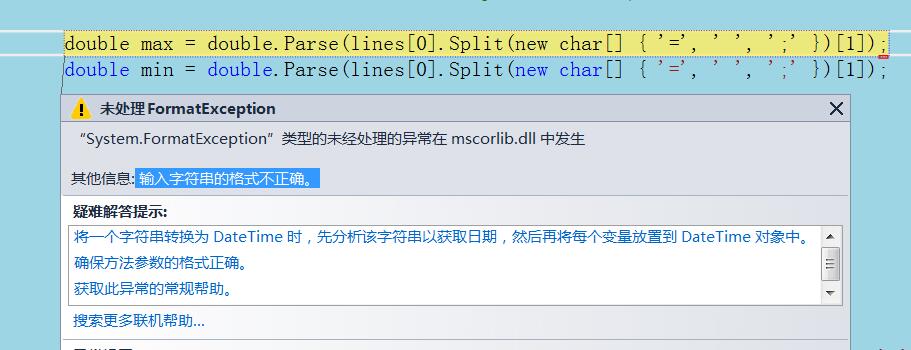
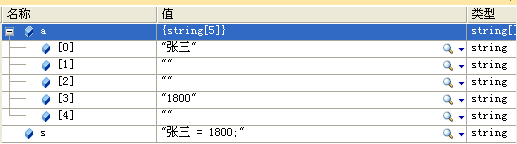
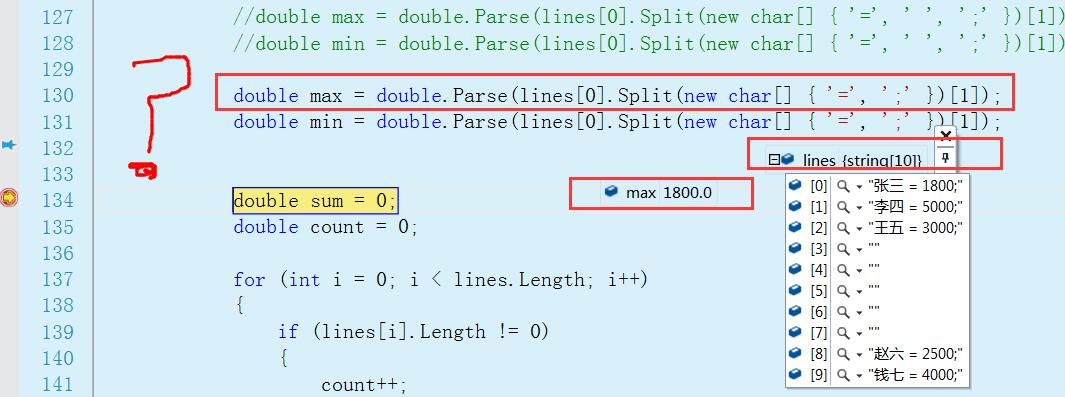
double max = double.Parse(lines[0].Split(new char[] { '=', ' ', ';' })[1]); //修改的代码
double min = double.Parse(lines[0].Split(new char[] { '=', ' ', ';' })[1]); //修改的代码
double sum = 0;
double count = 0;
for (int i = 0; i < lines.Length; i++)
{
if (lines[i].Length != 0)
{
count++;
double money = double.Parse(lines[i].Split(new char[] { '=', ' ', ';' })[1]); //修改的代码
sum += money;
if (max < money)
{
max = money;
}
if (min > money)
{
min = money;
}
} //if(lines[i].Length != 0)
}
Console.WriteLine("最高工资为{0}", max);
Console.WriteLine("最低工资为{0}", min);
Console.WriteLine("平均工资为{0}", (sum / count) );
Console.ReadKey();
}
}
}












//NAME: essaie bla bla
//DIMENSION: 8
//DATA
//1 14 15
//2 11 10
//3 6 4
//4 7 13
//5 9 21
//6 19 3
//7 1 5
//8 8 8
//EOF
//
// 文本文件中可能还含有其他内容,但是需要用到的内容即以上
//比如data.txt:
//NAME: essaie bla bla
//其它内容
//DIMENSION: 8
//其它内容
//DATA
//其它内容
//1 14 15
//其它内容
//2 11 10
//其它内容
//3 6 4
//其它内容
//4 7 13
//其它内容
//5 9 21
//其它内容
//6 19 3
//其它内容
//7 1 5
//其它内容
//8 8 8
//其它内容
//EOF
// 目标是要获取NAME后字串,DIMENSION后数值,以及DATA以下的数值
// 其中NAME就是随便个字句,DIMENSION是城市数量,DATA以下是城市编号,X坐标,Y坐标
// 所有的这些将赋值给一个事先定义好的结构
#include <stdio.h>
#include <string.h>
#define MAXCPL 80 //每行最大字符数
#define MAXCITY 100 //每组数据中DATA最多项数,DIMENSION的最大值
#define MAXNAMEL 32 //NAME最大长度
struct S {
char NAME[MAXNAMEL+1];
int DIMENSION;
struct D {
int NO;
int X;
int Y;
} DATA[MAXCITY];
} s;
FILE *f;
int st,n,i;
char ln[MAXCPL];
int main() {
f=fopen("data.txt","r");
if (NULL==f) {
printf("Can not open file data.txt!\n");
return 1;
}
st=0;
n=0;
while (1) {
if (NULL==fgets(ln,MAXCPL,f)) break;
if (st==0) {
if (1==sscanf(ln,"NAME: %31[^\n]",s.NAME)) st=1;
} else if (st==1) {
if (1==sscanf(ln,"DIMENSION: %d",&s.DIMENSION)) st=2;
} else if (st==2) {
if (0==strcmp(ln,"DATA\n")) st=3;
} else if (st==3) {
if (3==sscanf(ln,"%d%d%d",&s.DATA[n].NO,&s.DATA[n].X,&s.DATA[n].Y)) {
n++;
if (n>=MAXCITY || n>=s.DIMENSION) break;
}
}
}
fclose(f);
printf("s.NAME=[%s]\n",s.NAME);
printf("s.DIMENSION=%d\n",s.DIMENSION);
for (i=0;i<n;i++) {
printf("s.DATA[%d].NO,X,Y=%d,%d,%d\n",i,s.DATA[i].NO,s.DATA[i].X,s.DATA[i].Y);
}
return 0;
}
//s.NAME=[essaie bla bla]
//s.DIMENSION=8
//s.DATA[0].NO,X,Y=1,14,15
//s.DATA[1].NO,X,Y=2,11,10
//s.DATA[2].NO,X,Y=3,6,4
//s.DATA[3].NO,X,Y=4,7,13
//s.DATA[4].NO,X,Y=5,9,21
//s.DATA[5].NO,X,Y=6,19,3
//s.DATA[6].NO,X,Y=7,1,5
//s.DATA[7].NO,X,Y=8,8,8
#include <stdio.h>
#include <string.h>
char string[80];
char seps1[3];
char seps2[3];
char *token;
char *zzstrtok (
char *string,
const char *control1,//连续出现时视为中间夹空token
const char *control2 //连续出现时视为中间无空token
)
{
unsigned char *str;
const unsigned char *ctrl1 = (const unsigned char *)control1;
const unsigned char *ctrl2 = (const unsigned char *)control2;
unsigned char map1[32],map2[32];
static char *nextoken;
static char flag=0;
unsigned char c;
int L;
memset(map1,0,32);
memset(map2,0,32);
do {
map1[*ctrl1 >> 3] |= (1 << (*ctrl1 & 7));
} while (*ctrl1++);
do {
map2[*ctrl2 >> 3] |= (1 << (*ctrl2 & 7));
} while (*ctrl2++);
if (string) {
if (control2[0]) {
L=strlen(string);
while (1) {
c=string[L-1];
if (map2[c >> 3] & (1 << (c & 7))) {
L--;
string[L]=0;
} else break;
}
}
if (control1[0]) {
L=strlen(string);
c=string[L-1];
if (map1[c >> 3] & (1 << (c & 7))) {
string[L]=control1[0];
string[L+1]=0;
}
}
str=(unsigned char *)string;
}
else str=(unsigned char *)nextoken;
string=(char *)str;
while (1) {
if (0==flag) {
if (!*str) break;
if (map1[*str >> 3] & (1 << (*str & 7))) {
*str=0;
str++;
break;
} else if (map2[*str >> 3] & (1 << (*str & 7))) {
string++;
str++;
} else {
flag=1;
str++;
}
} else if (1==flag) {
if (!*str) break;
if (map1[*str >> 3] & (1 << (*str & 7))) {
*str=0;
str++;
flag=0;
break;
} else if (map2[*str >> 3] & (1 << (*str & 7))) {
*str=0;
str++;
flag=2;
break;
} else str++;
} else {//2==flag
if (!*str) return NULL;
if (map1[*str >> 3] & (1 << (*str & 7))) {
str++;
string=(char *)str;
flag=0;
} else if (map2[*str >> 3] & (1 << (*str & 7))) {
str++;
string=(char *)str;
} else {
string=(char *)str;
str++;
flag=1;
}
}
}
nextoken=(char *)str;
if (string==(char *)str) return NULL;
else return string;
}
void main()
{
strcpy(string,"A \tstring\t\tof ,,tokens\n\nand some more tokens, ");
strcpy(seps1,",\n");strcpy(seps2," \t");
printf("\n[%s]\nTokens:\n",string);
token=zzstrtok(string,seps1,seps2);
while (token!=NULL) {
printf(" <%s>",token);
token=zzstrtok(NULL,seps1,seps2);
}
strcpy(string,"1234| LIYI|China | 010 |201110260000|OK");
strcpy(seps1,"|");strcpy(seps2," ");
printf("\n[%s]\nTokens:\n",string);
token=zzstrtok(string,seps1,seps2);
while (token!=NULL) {
printf(" <%s>",token);
token=zzstrtok(NULL,seps1,seps2);
}
strcpy(string,"1234|LIYI||010|201110260000|OK");
strcpy(seps1,"");strcpy(seps2,"|");
printf("\n[%s]\nTokens:\n",string);
token=zzstrtok(string,seps1,seps2);
while (token!=NULL) {
printf(" <%s>",token);
token=zzstrtok(NULL,seps1,seps2);
}
strcpy(string,"1234|LIYI||010|201110260000|OK");
strcpy(seps1,"|");strcpy(seps2,"");
printf("\n[%s]\nTokens:\n",string);
token=zzstrtok(string,seps1,seps2);
while (token!=NULL) {
printf(" <%s>",token);
token=zzstrtok(NULL,seps1,seps2);
}
strcpy(string,"a");
strcpy(seps1,",");strcpy(seps2,"");
printf("\n[%s]\nTokens:\n",string);
token=zzstrtok(string,seps1,seps2);
while (token!=NULL) {
printf(" <%s>",token);
token=zzstrtok(NULL,seps1,seps2);
}
strcpy(string,"a,b");
strcpy(seps1,",");strcpy(seps2,"");
printf("\n[%s]\nTokens:\n",string);
token=zzstrtok(string,seps1,seps2);
while (token!=NULL) {
printf(" <%s>",token);
token=zzstrtok(NULL,seps1,seps2);
}
strcpy(string,"a,,b");
strcpy(seps1,",");strcpy(seps2,"");
printf("\n[%s]\nTokens:\n",string);
token=zzstrtok(string,seps1,seps2);
while (token!=NULL) {
printf(" <%s>",token);
token=zzstrtok(NULL,seps1,seps2);
}
strcpy(string,",a");
strcpy(seps1,",");strcpy(seps2,"");
printf("\n[%s]\nTokens:\n",string);
token=zzstrtok(string,seps1,seps2);
while (token!=NULL) {
printf(" <%s>",token);
token=zzstrtok(NULL,seps1,seps2);
}
strcpy(string,"a,");
strcpy(seps1,",");strcpy(seps2,"");
printf("\n[%s]\nTokens:\n",string);
token=zzstrtok(string,seps1,seps2);
while (token!=NULL) {
printf(" <%s>",token);
token=zzstrtok(NULL,seps1,seps2);
}
strcpy(string,",a,,b");
strcpy(seps1,",");strcpy(seps2,"");
printf("\n[%s]\nTokens:\n",string);
token=zzstrtok(string,seps1,seps2);
while (token!=NULL) {
printf(" <%s>",token);
token=zzstrtok(NULL,seps1,seps2);
}
strcpy(string,",,a,,b,,");
strcpy(seps1,",");strcpy(seps2,"");
printf("\n[%s]\nTokens:\n",string);
token=zzstrtok(string,seps1,seps2);
while (token!=NULL) {
printf(" <%s>",token);
token=zzstrtok(NULL,seps1,seps2);
}
strcpy(string,",");
strcpy(seps1,",");strcpy(seps2,"");
printf("\n[%s]\nTokens:\n",string);
token=zzstrtok(string,seps1,seps2);
while (token!=NULL) {
printf(" <%s>",token);
token=zzstrtok(NULL,seps1,seps2);
}
strcpy(string,",,");
strcpy(seps1,",");strcpy(seps2,"");
printf("\n[%s]\nTokens:\n",string);
token=zzstrtok(string,seps1,seps2);
while (token!=NULL) {
printf(" <%s>",token);
token=zzstrtok(NULL,seps1,seps2);
}
strcpy(string,",,,");
strcpy(seps1,",");strcpy(seps2," ");
printf("\n[%s]\nTokens:\n",string);
token=zzstrtok(string,seps1,seps2);
while (token!=NULL) {
printf(" <%s>",token);
token=zzstrtok(NULL,seps1,seps2);
}
}
//
//[A string of ,,tokens
//
//and some more tokens,]
//Tokens:
// <A>, <string>, <of>, <>, <tokens>, <>, <and>, <some>, <more>, <tokens>, <>,
//[1234| LIYI|China | 010 |201110260000|OK]
//Tokens:
// <1234>, <LIYI>, <China>, <010>, <201110260000>, <OK>,
//[1234|LIYI||010|201110260000|OK]
//Tokens:
// <1234>, <LIYI>, <010>, <201110260000>, <OK>,
//[1234|LIYI||010|201110260000|OK]
//Tokens:
// <1234>, <LIYI>, <>, <010>, <201110260000>, <OK>,
//[a]
//Tokens:
// <a>,
//[a,b]
//Tokens:
// <a>, <b>,
//[a,,b]
//Tokens:
// <a>, <>, <b>,
//[,a]
//Tokens:
// <>, <a>,
//[a,]
//Tokens:
// <a>, <>,
//[,a,,b]
//Tokens:
// <>, <a>, <>, <b>,
//[,,a,,b,,]
//Tokens:
// <>, <>, <a>, <>, <b>, <>, <>,
//[,]
//Tokens:
// <>, <>,
//[,,]
//Tokens:
// <>, <>, <>,
//[,,,]
//Tokens:
// <>, <>, <>, <>,
//凡是?。!后面跟1~1000后面跟半角.的,在?。!后面加回车换行。
//in.txt:
//1.测试。2.测试2?3.测试3!4.测试
//四。5.测试。6.测试6?7.测试3!8.测试
//运行该程序将输出重定向到比如out.txt即可将输出保存到文件out.txt中
#include <iostream>
#include <fstream>
#include <string>
#include <regex>
using namespace std;
int main() {
wifstream wifs("in.txt");
wifs.imbue(locale("chs"));
wstring wstr(L""),wln;
while (wifs) {
getline(wifs,wln);
wstr+=wln;
}
wifs.close();
wcout.imbue(locale("chs"));
wcout << wstr << endl;
wstring rs = L"([?。!])(\\d{1,3}\\.)";
wregex expression(rs);
wstr = regex_replace(wstr, expression, wstring(L"$1\r\n$2"));
wcout << wstr << endl;
return 0;
}
//1.测试。2.测试2?3.测试3!4.测试四。5.测试。6.测试6?7.测试3!8.测试
//1.测试。
//2.测试2?
//3.测试3!
//4.测试四。
//5.测试。
//6.测试6?
//7.测试3!
//8.测试
//




