社区
OpenCL和异构编程
帖子详情
intel 平台运行opencl出现的问题不存在从cl_device_id转到cl::Device适当的构造函数
P_B_Y
2016-10-20 08:49:08
求各位大神帮忙解决
...全文
1445
回复
打赏
收藏
intel 平台运行opencl出现的问题不存在从cl_device_id转到cl::Device适当的构造函数
求各位大神帮忙解决
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
ec_o
cl
:椭圆曲线
Open
CL
实现
ec_o
cl
标量点乘法的椭圆曲线
Open
CL
实现 地位:
cl
_amd 测试程序分 2 组执行 8 个工作项,读取和存储,计算并写回主机。 主机程序编译 o
cl
内核,使用 _constant 和 _local 地址空间分配和执行内存传输。 在 _local 地址空间上写入,从 _constant 读取,然后导出到 _global NDRange 中的每个工作项都执行相同的“好”计算。
cl
_amd # ./demo ec_p_mul.
cl
point_mul Check
Open
CL
environtment Connecting to
Open
CL
device
: AuthenticAMD AMD E-350 Processor
CL
_
DEVICE
_MAX_COMPUTE_UNITS 2
CL
_
DEVICE
_MAX_WORK_GROUP_SIZE 1024
c_
open
cl
_wrapper:常见
Open
CL
用法的简单包装器
Open
cl
C API 包装器 常见
Open
CL
用法的简单包装器。 使用示例 host.c : # in
cl
ude < stdio> # in
cl
ude "
open
cl
.h " main () { uint i, n = 1000 ; real * v = (real *) malloc (n * sizeof (real)); for (i= 0 ; i<n; i++) v[i] = (real)i; // mandatory initialization
open
cl
_init ( 0 ,
CL
_
DEVICE
_TYPE_GPU); // creating variables on
device
(and enqueing data copy)
cl
_var dn =
open
cl
_create_var ( sizeof ( uint ), 1 ,
Delphi XE2的
Open
CL
控件(可以象TQuery一样使用
Open
CL
)
这是一个基于Delphi XE2的
Open
CL
控件。其中使用到了Khronos Group Inc.的
CL
.pas单元。
Open
CL
的设计思路和OpenGL类似,对于大部分Delphi的设计者来说,非常不习惯,而且使用起来并不十分方便 设计这个T
Open
CL
控件的目的不是替代
Open
CL
的原生使用方式,而是为了开发者能够快速对
Open
CL
进行应用并且可以 用来测试性能和功能。 使用T
Open
CL
控件,可以象使用数据库控件那样方便的去调用
Open
CL
程序,不需要太多代码就可以
运行
一个
Open
CL
的Kernel。这对于学习和深入研究
Open
CL
的性能有一个很好的铺垫。 使用
Open
CL
做并行计算的一个主要因素就是提高大数据量计算的速度,这和通常的业务处理类程序大不相同,因 此提升
Open
CL
的
运行
效率是至关重要的,本控件附带的Demo程序中,是对两个长度分别为8192和32的float数组,进行 一维卷积计算的。在选择不同的数据传递方式(如使用显存还是Host内存、使用只读方式还是可读写或者只写方式), 或者不同的
Device
(如在多核CPU上和GPU上
运行
Kernel程序)上
运行
,其效率相差是非常大的。 Demo程序中缺省的使用不显示获取结果的方式
运行
,缺省的数据传输是使用显存(CPU作为
Device
的时候,其实还 是系统内存)并Copy数据的方式,因此显示结果始终是0。当输出的参数传递方式改为直接使用系统内存指针的方式时, 不使用显示获取计算结果则是可以得到运算结果的。这些参数之间的差异,读者自行测试并仔细体会,通过调整,相信 可以得到最佳的
运行
方式。 Demo中包含了四个Kernel函数,分别是Convolution_Kernel_With_Barrier。这是一个带有同步函数Barrier的卷积 过程,并在卷积完成后,等待所有单元计算完毕,然后对结果进行微分(差商)处理,实际情况表明Barrier函数对GPU 的影响甚微,但如果使用CPU作为
Device
计算,则效率影响非常大,其耗时几乎和单核计算不相上下,估计是同步函数 在等候的过程中,引起了CPU对Catch竞争访问的结果吧。对这种情况,反倒不如拆分成两个Kernel进行单独计算,其累 积的计算时间基本上为两个独立Kernel耗时只和。 Differ_Kernel是单独进行微分计算的,是为了验证上面计算耗时结果的。 Convolution_Kernel是只进行卷积计算的,可以认为和Differ_Kernel前后执行,其结果应该和Convolution_Kerne- l_With_Barrier单独执行是一样的。 Convolution则是一个简单的计算过程,用来测试启动Kernel、等候数据等操作会占用的时间情况的。
Open
CL
其实并不是想象中那么美妙,也不是想象中的那么复杂,但要使用好
Open
CL
,就必须认真的对待每个细节, 甚至到每一个函数调用或者if控制等,大家可以参考“http://hi.ba
id
u.com/fsword73”,上面涉及到的很多方面,都是 可以提升Kernel
运行
效率的。 目前这个T
Open
CL
控件只是作者为了测试
Open
CL
运行
效率编写的一个小的工具,作为一个测试工具或者技术积累阶段 的工具足矣,但在实际工程中,希望还是能够尽可能使用原生的调用方式,控件模式势必会带来一定的性能损失的,这是 无法克服的是一个实际情况,对于某些流式数据处理的计算而言,多次重复使用同一个Kernel对流式数据进行处理的,则 使用本控件应该不会造成太大的性能影响。 目前T
Open
CL
不支持多个
Device
同时工作,可以选择CPU、GPU或者APU作为首选设备, X86下
运行
正常,X64下
运行
仍有
问题
,疑和
cl
.pas中对context等处理的方式不支持X64或者其他原因。 目前支持的
Open
CL
版本为1.2。控件没有考虑
Open
CL
和OpenGL协同工作的情况,需要做这方面应用或者测试的读者,请 自行处理。 一下是控件几个主要类的引用关系图。供参考。 由于时间的关系,不可能提供详细的使用说明,往谅解,有
问题
可邮件与作者联系或者QQ联系。 Mail:18909181984@189.cn QQ:57440981 T
Open
CL
--| | |--T
cl
Kernels --| |--- T
cl
Kernel --| | |-- T
cl
K
【BUG】
cl
CreateKernel:
open
cl
error: -6,
CL
_OUT_OF_HOST_MEMORY
cl
CreateKernel:
open
cl
error: -6,
CL
_OUT_OF_HOST_MEMORY 今天调试
Open
CL
代码写了一个memcpy的函数,发现调用
cl
CreateKernel()函数产生了错误,err:-6
CL
_OUT_OF_HOST_MEMORY :宿主机上没有足够的内存执行命令 由于官方解释的原因就是这样,所以我的关注重点放在了内存上面,找了半天也没有发现
问题
原因。 突然间猛然想到,是不是函数本生的使用产生了
问题
,于是将重点放在了函数功能上,在实现函数的功能所依赖的kern
Open
CL
使用子缓冲对象(Sub buffer)报错
CL
_
DEVICE
_MEM_BASE_ADDR_ALIGN的解决方法
最近由于新冠疫情原因宅于家中,不得不重新搞个电脑继续毕设之旅,学校所用电脑为i5-6500+Titan xp,在家只能自掏腰包配了个i5-9400f + 1660,CPU升级了下,GPU看看就好。 废话不说了,直奔主题。 在使用
Open
CL
创建子缓冲对象时,使用 i5-9400f CPU 作为计算设备会
出现
CL
_
DEVICE
_MEM_BASE_ADDR_ALIGN,而对于相同的程序,GPU则...
OpenCL和异构编程
603
社区成员
575
社区内容
发帖
与我相关
我的任务
OpenCL和异构编程
异构开发技术
复制链接
扫一扫
分享
社区描述
异构开发技术
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章
 P_B_Y 2016-10-20 08:49:08
P_B_Y 2016-10-20 08:49:08 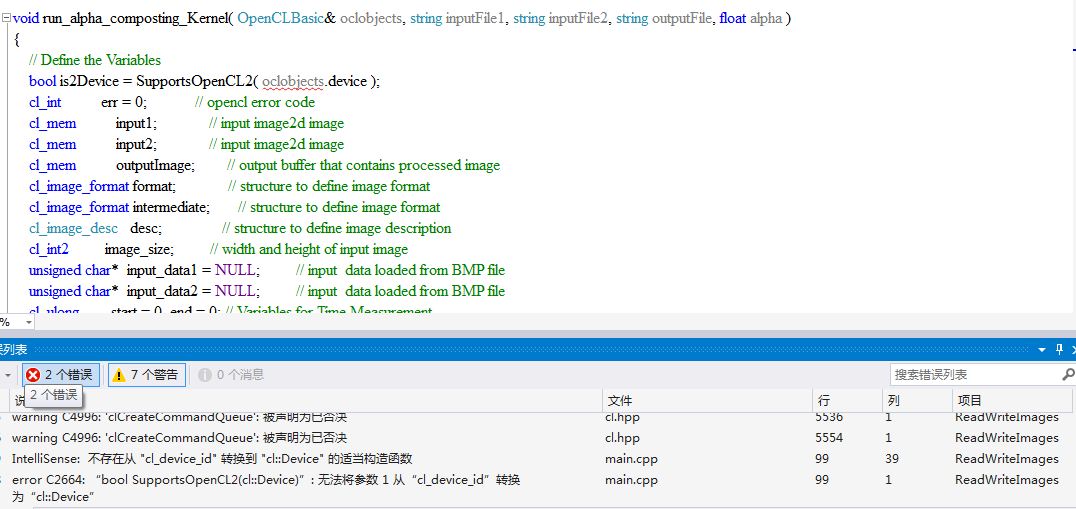
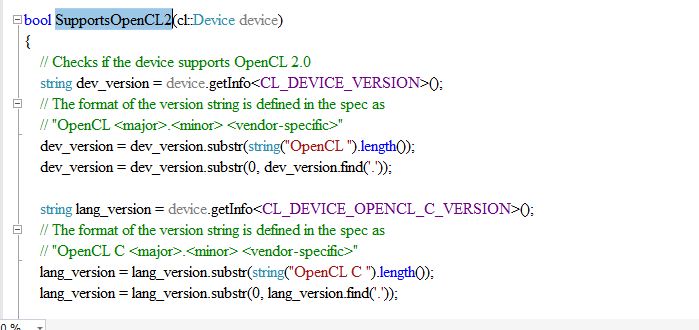



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享