


8,906
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享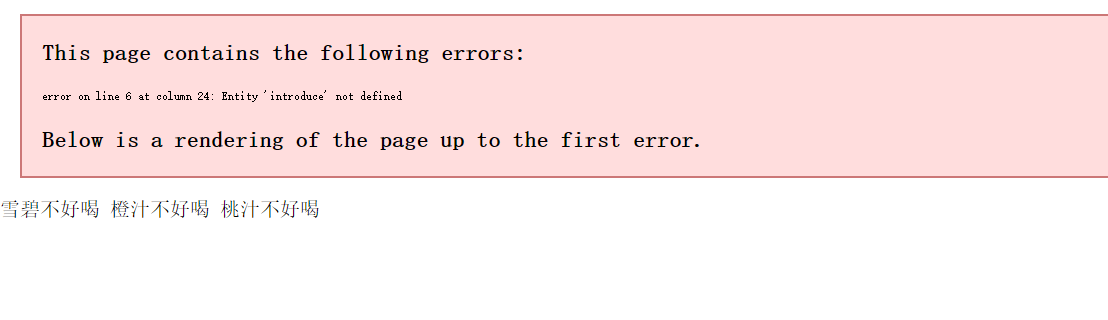

<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<!DOCTYPE 饮料[
<!ELEMENT 饮料 (碳酸饮料,果汁饮料)*>
<!ELEMENT 碳酸饮料 (可乐,雪碧)>
<!ELEMENT 果汁饮料 (橙汁,桃汁)>
<!ELEMENT 可乐 (#PCDATA)>
<!ELEMENT 雪碧 (#PCDATA)>
<!ELEMENT 橙汁 (#PCDATA)>
<!ELEMENT 桃汁 (#PCDATA)>
<!ENTITY introduce SYSTEM "introduce.txt">
]>
<饮料>
<碳酸饮料>
<可乐>&introduce;</可乐>
<雪碧>不爱喝雪碧</雪碧>
</碳酸饮料>
<果汁饮料>
<橙汁>不爱喝橙汁</橙汁>
<桃汁>不爱喝桃汁</桃汁>
</果汁饮料>
</饮料><?xml version="1.0" encoding="UTF-8"?>
可口可乐是一种非常非常好喝的饮料,但是喝多了对身体不好哦。一个月喝一次就行了

