

696
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享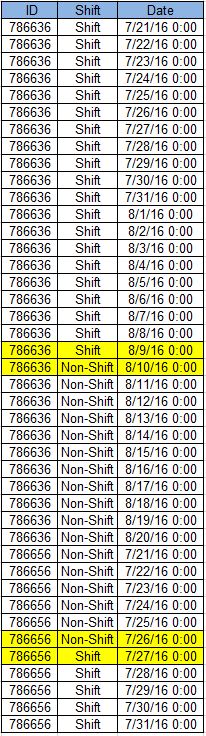




with tb(_ID, _shift, _date) as
(
select 986636, 'Shift', '2016.07.21' union all
select 986636, 'Shift', '2016.07.22' union all
select 986636, 'Non-Shift', '2016.07.23' union all
select 986636, 'Non-Shift', '2016.07.24' union ALL
select 986636, 'Non-Shift', '2016.07.25' union all
select 986636, 'Shift', '2016.07.26' union all
select 986636, 'Shift', '2016.07.27' union all
select 986636, 'Shift', '2016.07.28'
),
cte AS (
SELECT rn=ROW_NUMBER() OVER(ORDER BY _date),* FROM tb
)
SELECT * FROM cte a JOIN cte b ON ABS(a.rn-b.rn)=1 WHERE a.[_shift]<>b.[_shift]

with tb(_ID, _shift, _date) as
(
select 986636, 'Shift', '2016.07.21' union all
select 986636, 'Shift', '2016.07.22' union all
select 986636, 'Non-Shift', '2016.07.23' union all
select 986636, 'Non-Shift', '2016.07.24' union ALL
select 986636, 'Non-Shift', '2016.07.25' union all
select 986636, 'Shift', '2016.07.26' union all
select 986636, 'Shift', '2016.07.27' union all
select 986636, 'Shift', '2016.07.28'
)
,CTE AS(
SELECT *,
ROW_NUMBER() OVER (PARTITION BY tb._ID ORDER BY tb._date) AS RNr
FROM tb
)
SELECT * FROM CTE b WHERE EXISTS(
SELECT *
FROM CTE a
WHERE EXISTS(SELECT * FROM CTE WHERE a._ID = CTE._ID AND RNr = a.RNr + 1 AND a._shift <> CTE._shift)
AND b.RNr IN (a.RNr,a.RNr+1))

with tb(ID, shift, d) as
(
select 986636, 'Shift', '2016.07.21' union all
select 986636, 'Shift', '2016.07.22' union all
select 986636, 'Non-Shift', '2016.07.23' union all
select 986636, 'Non-Shift', '2016.07.24' union all
select 986636, 'Shift', '2016.07.25' union all
select 986636, 'Shift', '2016.07.26' union all
select 986636, 'Shift', '2016.07.27'
)
SELECT t.*,t1.shift,t2.shift
FROM tb AS t
OUTER APPLY (SELECT TOP 1 pt.shift FROM tb AS pt WHERE pt.id=t.id AND pt.d<t.d ORDER BY pt.d DESC ) t1
OUTER APPLY (SELECT TOP 1 lt.shift FROM tb AS lt WHERE lt.id=t.id AND lt.d>t.d ORDER BY lt.d ) t2
WHERE t.shift!= ISNULL(t1.shift,t.shift) OR t.shift!=ISNULL(t2.shift,t.shift)
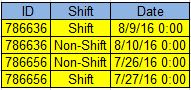
/*
ID shift d
----------- --------- ----------
986636 Shift 2016.07.22
986636 Non-Shift 2016.07.23
986636 Non-Shift 2016.07.24
986636 Shift 2016.07.25
*/

