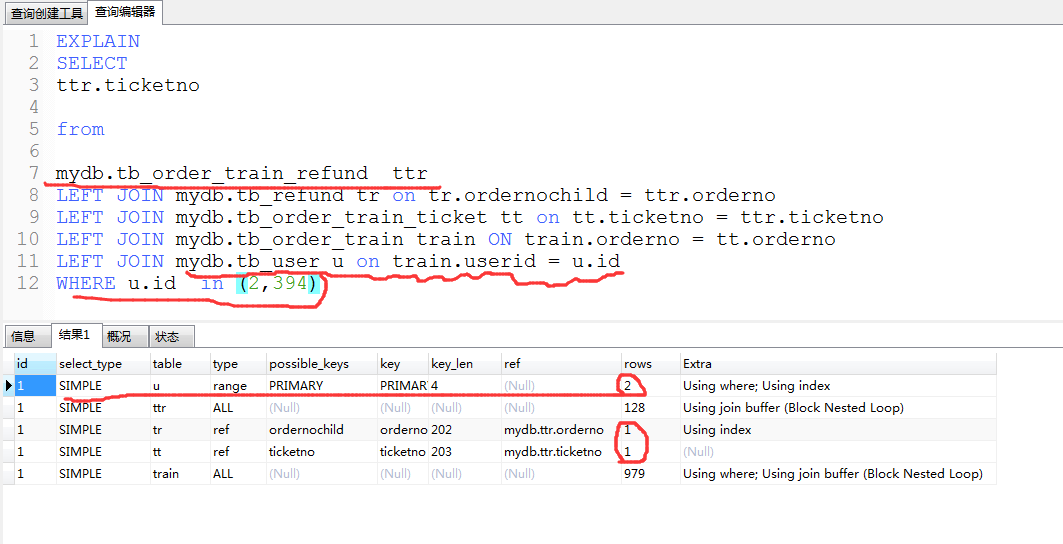
[quote=引用 6 楼 yupeigu 的回复:] 确实是id相同的,从上往下执行。 至于,这个执行计划,确实不好理解,不像sql server那样有图形化的执行计划,一目了然,mysql中的执行计划都是文本型的,哪个表和那个表,先关联,之后做什么都不是很清晰。 我觉得大致的过程是这样的,首先u过滤只有2条数据,而且是主键过滤,效率很高。 然后,ttr是全表扫描,每次与tr关联,是用的tr的索引,然后tr和tt关联,用的是tt的索引
确实是id相同的,从上往下执行。 至于,这个执行计划,确实不好理解,不像sql server那样有图形化的执行计划,一目了然,mysql中的执行计划都是文本型的,哪个表和那个表,先关联,之后做什么都不是很清晰。 我觉得大致的过程是这样的,首先u过滤只有2条数据,而且是主键过滤,效率很高。 然后,ttr是全表扫描,每次与tr关联,是用的tr的索引,然后tr和tt关联,用的是tt的索引
引用 2 楼 VertigozZ 的回复:U 和 ttr 没有做关联 ,优先解析u表 后 再解析 ttr 他们怎么关联的 让我想不明白贴出来的解析结果是最终解析结果,没有关联的信息,毕竟把具体的解析过程贴出来也没什么必要
U 和 ttr 没有做关联 ,优先解析u表 后 再解析 ttr 他们怎么关联的 让我想不明白
57,064
社区成员
56,760
社区内容
加载中
试试用AI创作助手写篇文章吧


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



