社区
Cloud Foundry
帖子详情
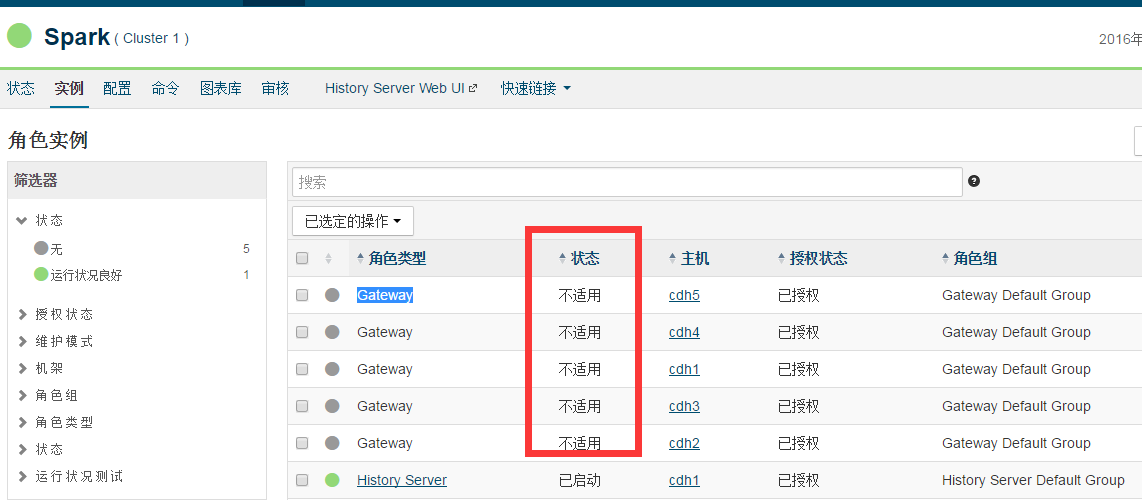
使用cdh5.8.3安装完spark之后,发现spark角色类型Gateway显示的状态为“不适用”,请问正常吗
liygcoding
2016-12-15 04:23:17
1)使用cdh5.8.3安装完spark之后,发现spark角色类型Gateway显示的状态为“不适用”,请问正常吗
2) 使用cdh5安装完spark后,难道还需要手工配置一些文件才能让gateway显示正常吗?
3)cdh5自带的spark前台显示gateway状态怎么样才算正确呢?
...全文
10273
4
打赏
收藏
使用cdh5.8.3安装完spark之后,发现spark角色类型Gateway显示的状态为“不适用”,请问正常吗
1)使用cdh5.8.3安装完spark之后,发现spark角色类型Gateway显示的状态为“不适用”,请问正常吗 2) 使用cdh5安装完spark后,难道还需要手工配置一些文件才能让gateway显示正常吗? 3)cdh5自带的spark前台显示gateway状态怎么样才算正确呢?
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
4 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
夜间独白
2019-01-09
打赏
举报
回复
感觉这个状态是正常的今天,弄了好久的这个网关,都是不适用,但是也不会影响程序运行,如果spark on yarn 跑的运行失败,不放试试su hdfs,在hdfs 下执行spark-submit。我自己感觉cdh安装的spark(on yarn就是上面那个,下面还有一个单机版好像)应该有个自带yarn,可以提交,默认是用这个,所以还需要自己调整环境,配置一些权限。
Xiao 伙伴
2017-01-07
打赏
举报
回复
正常现象,gateway只是spark任务提交的入口,只配置一个history server其实就够了
liygcoding
2016-12-15
打赏
举报
回复
期待大神的回答!非常感谢!!!
CD
H环境故障:linux jdk环境部署不规范导致部署
spark
2
gateway
失败,
spark
2-submit无法执行
问题概述 在
CD
H中离线部署
完
spark
2
之后
,执行
spark
2-submit命令测试部署的
spark
2是否可用,结果立即提示请
安装
spark
gateway
角色
。说明我的
spark
2并未成功部署,或者它依赖的环境没有满足 问题详情 问题出现 如图,在
spark
2集群页面,选择【部署客户端配置操作】 一段时间后,部署崩溃! 查看日志 查看崩溃的日志,
spark
2部署的每个客户端有2份日志,1份stout,1份sterr stout日志 sterr日...
studio找不到jdk_
CD
H环境故障:jdk环境部署不规范导致
spark
2submit无法执行
问题概述在
CD
H中离线部署
完
spark
2
之后
,执行
spark
2-submit命令测试部署的
spark
2是否可用,结果立即提示请
安装
spark
gateway
角色
。说明我的
spark
2并未成功部署,或者它依赖的环境没有满足1、问题详情1.1 问题出现如图,在
spark
2集群页面,选择【部署客户端配置操作】一段时间后,部署崩溃!1.2 查看日志查看崩溃的日志,
spark
2部署的每个客...
Cloudera Manager 5.9 和
CD
H 5.9 离线
安装
指南及个人采坑填坑记
公司的
CD
H早就装好了,一直想自己装一个玩玩,最近组了台电脑,笔记本就淘汰下来了,加上之前的,一共3台,就在X宝上买了CPU和内存升级了下笔记本,就自己组了个集群。 话说,好想去捡垃圾,捡台8核16线程64G内存的回来,手动滑稽。 3台笔记本的配置和
角色
分配: 宿主CPU 宿主内存 虚拟机 虚拟机CPU/台
角色
及内存 双核双线程 4G 1台
Cloudera Manager及
CD
H最新版本
安装
全程记录
Cloudera Manager及
CD
H最新版本
安装
全程记录 大家都知道,Apache Hadoop的配置很繁琐,而且很零散,为此Cloudera公司提供了Clouder Manager工具,而且还封装了Apache Hadoop,flume,
spark
,hive,hbase等大数据产品形成自己特色的
CD
H产品,再
使用
CM进行
安装
,很大程度上方便了集群的搭建,并提供了集群的监控功能。 一、环境: ...
CD
H
安装
公司的
CD
H早就装好了,一直想自己装一个玩玩,最近组了台电脑,笔记本就淘汰下来了,加上之前的,一共3台,就在X宝上买了CPU和内存升级了下笔记本,就自己组了个集群。 话说,好想去捡垃圾,捡台8核16线程64G内存的回来,手动滑稽。 3台笔记本的配置和
角色
分配: 宿主CPU 宿主内存 虚拟机 虚拟机CPU/台
角色
及内存 双核双线程 4G 1台
Cloud Foundry
547
社区成员
350
社区内容
发帖
与我相关
我的任务
Cloud Foundry
Cloud Foundry是业界第一个开源PaaS云平台,它支持多种框架、语言、运行时环境、云平台及应用服务,使开发人员能够在几秒钟内进行应用程序的部署和扩展,无需担心任何基础架构的问题。
复制链接
扫一扫
分享
社区描述
Cloud Foundry是业界第一个开源PaaS云平台,它支持多种框架、语言、运行时环境、云平台及应用服务,使开发人员能够在几秒钟内进行应用程序的部署和扩展,无需担心任何基础架构的问题。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



