社区
搜索引擎技术
帖子详情
关于抓取的百度搜索内容和实际浏览器打开的搜索内容不一样的问题
R_ine
2016-12-16 11:12:40
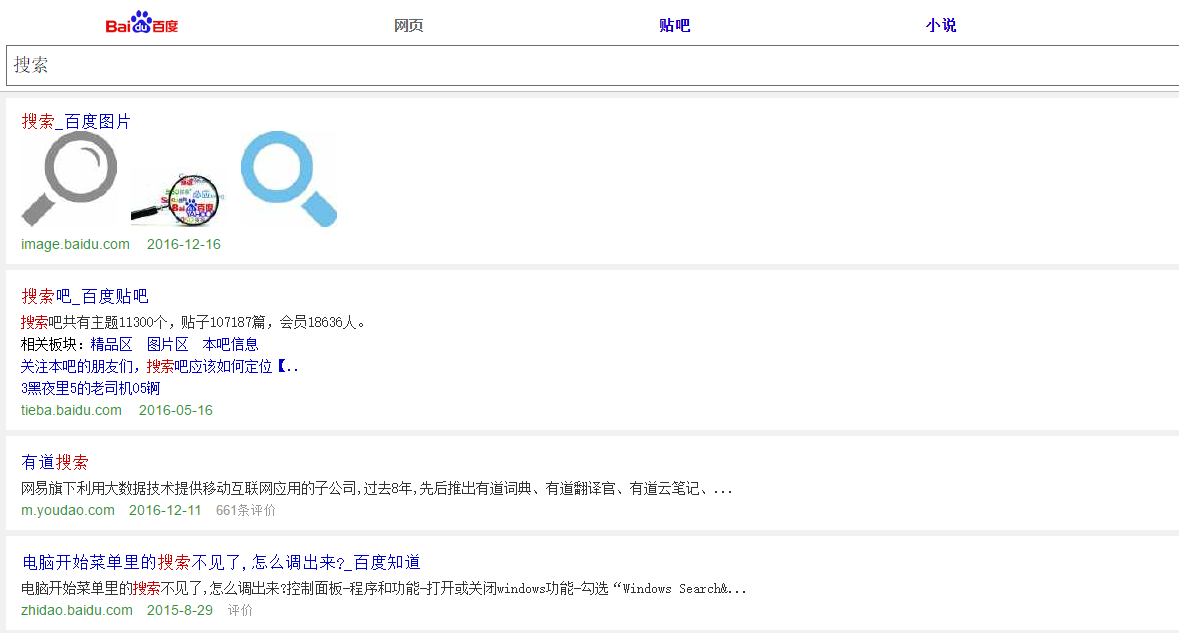
就是我用java抓取了某个词的百度搜索的源码,但获取到的html代码=-=和浏览器访问某个词的百度搜索内容,不一样。
这是为什么=-=
比如我搜索关键词“搜索”:
我用java获取到的页面:
但我用浏览器实际打开的页面是:
怎么才能2个页面一样呢=-=
...全文
1051
1
打赏
收藏
关于抓取的百度搜索内容和实际浏览器打开的搜索内容不一样的问题
就是我用java抓取了某个词的百度搜索的源码,但获取到的html代码=-=和浏览器访问某个词的百度搜索内容,不一样。 这是为什么=-= 比如我搜索关键词“搜索”: 我用java获取到的页面: 但我用浏览器实际打开的页面是: 怎么才能2个页面一样呢=-=
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
1 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
孟子E章
2016-12-16
打赏
举报
回复
你可以使用Http抓包工具查看提交到参数,都写到你的代码中应该就相同了,另外注意看浏览器是否使用了ajax查询了某些数据, 其实浏览器也是程序写的
Python-
抓取
股票信息
学习利用
抓取
股票信息
python selenium
抓取
网页源码与看到的
内容
不一致 解析
python selenium
抓取
网页源码与看到的
内容
不一致以天眼查一个公司的信息为例显示
内容
与源码不一致,很明显使用了加密进行font文件查看是不是这里面动了手脚如何解决这个
问题
呢? 以天眼查一个公司的信息为例 网站地址:https://www.tianyancha.com/company/100360072 网页核准日期显示的时间如下: 结果发现信息不一致, 为什么不一样?? 显示
内容
与源码不一致,很明显使用了加密 当时猜测的是应该是在字体上动了手脚,然后就查看了一下,总共有两个font文件。 进行
python爬虫爬取的数据与
浏览器
获取的数据不一样 爬虫爬取到的数据一直不变
具体
问题
在爬取某个网站时遇到了一个奇怪的
问题
,就是只要是python爬取的数据得到的基本就是那么几种数据,无论我输入的是什么,返回的数据与
浏览器
得到返回的数据都不一样,这让我很郁闷,
百度
也找不到想要的答案。直到最后才发现是自己对python不够了解,不是网站
问题
,是自己的
问题
。 解决方法 在requests库中,requests.post()方法中构造参数data时,data里面非ASCI...
如何获取微信
浏览器
访问需要OAuth2.0网页授权的页面资源
目标:需要获取一些微信网页的前端资源,嘿嘿,你懂的。 方法: 方法一:用chrome模拟微信
浏览器
,这个需要OAuth2.0授权的网页就获取不了啦。。。 方法二:
百度
了说可以用PHP的代码模拟访问,测试了也不行,
实际
结果与方法一一致。 方法三:采用fiddler抓包,成功达到目的,具体操作参照以下资源, 1、在
实际
的操作中,发现用汉化的fiddler
抓取
不了。于是在https://pc....
搜索引擎技术
2,760
社区成员
2,052
社区内容
发帖
与我相关
我的任务
搜索引擎技术
搜索引擎的服务器通过网络搜索软件或网络登录等方式,将Internet上大量网站的页面信息收集到本地,经过加工处理建立信息数据库和索引数据库。
复制链接
扫一扫
分享
社区描述
搜索引擎的服务器通过网络搜索软件或网络登录等方式,将Internet上大量网站的页面信息收集到本地,经过加工处理建立信息数据库和索引数据库。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章
 R_ine 2016-12-16 11:12:40
R_ine 2016-12-16 11:12:40 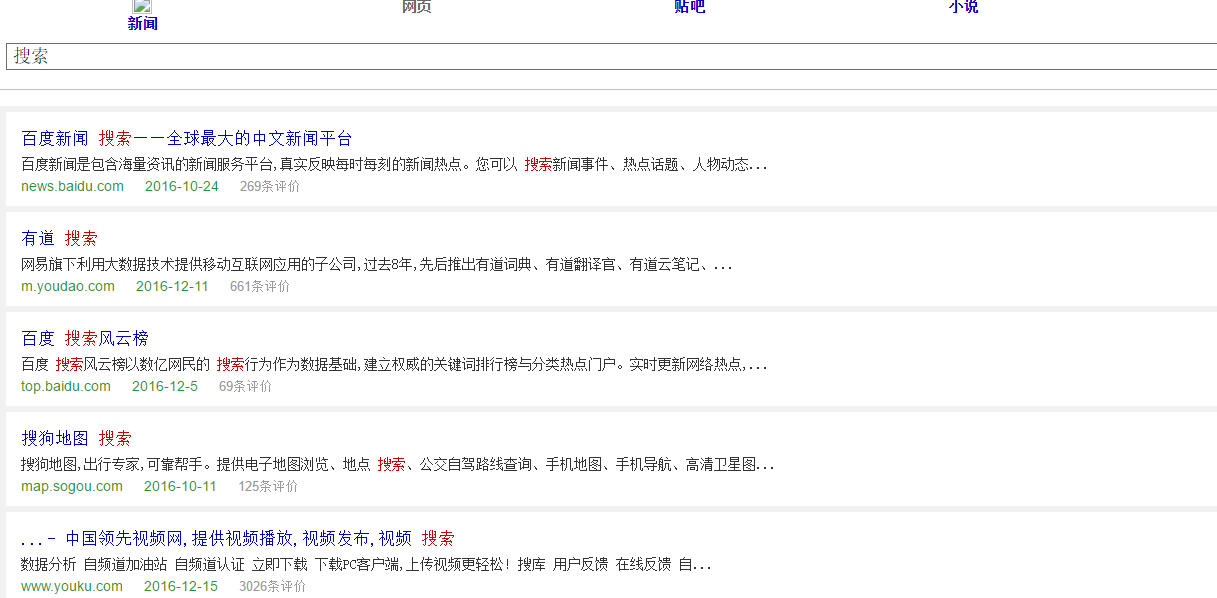



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

