


5,530
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享







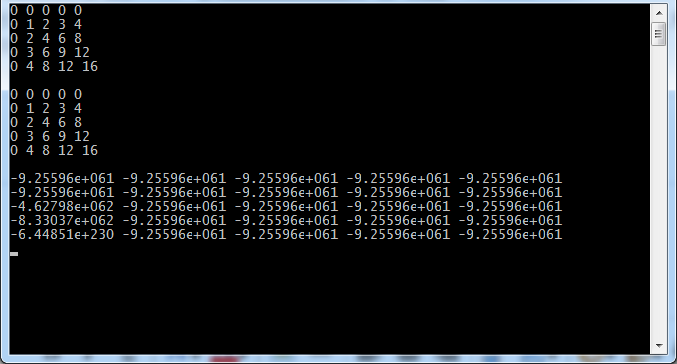 [/quote]
你应该没搞对,给下你完整代码[/quote]
[/quote]
你应该没搞对,给下你完整代码[/quote]
#include <vector>
#include <iostream>
using namespace std;
#define CACHE_LINE_SIZE 64
#define SM (CACHE_LINE_SIZE / sizeof(double))
int main()
{
double matrix1[5][5];
double matrix2[5][5];
double res3[5][5];
//initialize
for(int i=0;i<5;i++)
{
for(int j=0;j<5;j++)
{
matrix1[i][j] = i*j;
matrix2[i][j] = i*j;
}
}
for(int i=0;i<5;i++)
{
for(int j=0;j<5;j++)
{
cout<<matrix1[i][j]<<" ";
}
cout<<endl;
}
cout<<endl;
for(int i=0;i<5;i++)
{
for(int j=0;j<5;j++)
{
cout<<matrix2[i][j]<<" ";
}
cout<<endl;
}
cout<<endl;
int N=5;
int i2, j2, k2;
double* rres, *rm1, *rm2;
for (int i = 0; i < N; i += SM)
for (int j = 0; j < N; j += SM)
for (int k = 0; k < N; k += SM)
for (i2 = 0, rres = &res3[i][j], rm1 = &matrix1[i][k]; i2 < SM; ++i2, rres +=N, rm1 += N)
for (k2 = 0, rm2 = &matrix2[k][j]; k2 < SM; ++k2, rm2 += N)
for (j2 = 0; j2 < SM; ++j2)
rres[j2] += rm1[k2] * rm2[j2];
for(int i=0;i<5;i++)
{
for(int j=0;j<5;j++)
{
cout<<res3[i][j]<<" ";
}
cout<<endl;
}
return 0;
}
 [/quote]
[/quote]
#include <vector>
#include <iostream>
using namespace std;
#define CACHE_LINE_SIZE 64
#define SM (CACHE_LINE_SIZE / sizeof(double))
#define N 8
int main()
{
double matrix1[N][N];
double matrix2[N][N];
double res3[N][N]={0};
//initialize
for(int i=0;i<N;i++)
{
for(int j=0;j<N;j++)
{
matrix1[i][j] = i*j;
matrix2[i][j] = i*j;
}
}
for(int i=0;i<N;i++)
{
for(int j=0;j<N;j++)
{
cout<<matrix1[i][j]<<" ";
}
cout<<endl;
}
cout<<endl;
for(int i=0;i<N;i++)
{
for(int j=0;j<N;j++)
{
cout<<matrix2[i][j]<<" ";
}
cout<<endl;
}
cout<<endl;
int i2, j2, k2;
double* rres, *rm1, *rm2;
for (int i = 0; i < N; i += SM)
for (int j = 0; j < N; j += SM)
for (int k = 0; k < N; k += SM)
for (i2 = 0, rres = &res3[i][j], rm1 = &matrix1[i][k]; i2 < SM; ++i2, rres +=N, rm1 += N)
for (k2 = 0, rm2 = &matrix2[k][j]; k2 < SM; ++k2, rm2 += N)
for (j2 = 0; j2 < SM; ++j2)
rres[j2] += rm1[k2] * rm2[j2];
for(int i=0;i<N;i++)
{
for(int j=0;j<N;j++)
{
cout<<res3[i][j]<<" ";
}
cout<<endl;
}
return 0;
}

 [/quote]
你应该没搞对,给下你完整代码[/quote]
[/quote]
你应该没搞对,给下你完整代码[/quote]
#include <vector>
#include <iostream>
using namespace std;
#define CACHE_LINE_SIZE 64
#define SM (CACHE_LINE_SIZE / sizeof(double))
int main()
{
double matrix1[5][5];
double matrix2[5][5];
double res3[5][5];
//initialize
for(int i=0;i<5;i++)
{
for(int j=0;j<5;j++)
{
matrix1[i][j] = i*j;
matrix2[i][j] = i*j;
}
}
for(int i=0;i<5;i++)
{
for(int j=0;j<5;j++)
{
cout<<matrix1[i][j]<<" ";
}
cout<<endl;
}
cout<<endl;
for(int i=0;i<5;i++)
{
for(int j=0;j<5;j++)
{
cout<<matrix2[i][j]<<" ";
}
cout<<endl;
}
cout<<endl;
int N=5;
int i2, j2, k2;
double* rres, *rm1, *rm2;
for (int i = 0; i < N; i += SM)
for (int j = 0; j < N; j += SM)
for (int k = 0; k < N; k += SM)
for (i2 = 0, rres = &res3[i][j], rm1 = &matrix1[i][k]; i2 < SM; ++i2, rres +=N, rm1 += N)
for (k2 = 0, rm2 = &matrix2[k][j]; k2 < SM; ++k2, rm2 += N)
for (j2 = 0; j2 < SM; ++j2)
rres[j2] += rm1[k2] * rm2[j2];
for(int i=0;i<5;i++)
{
for(int j=0;j<5;j++)
{
cout<<res3[i][j]<<" ";
}
cout<<endl;
}
return 0;
}
#include <vector>
#include <iostream>
using namespace std;
#define CACHE_LINE_SIZE 64
#define SM (CACHE_LINE_SIZE / sizeof(double))
#define N 8
int main()
{
double matrix1[N][N];
double matrix2[N][N];
double res3[N][N]={0};
//initialize
for(int i=0;i<N;i++)
{
for(int j=0;j<N;j++)
{
matrix1[i][j] = i*j;
matrix2[i][j] = i*j;
}
}
for(int i=0;i<N;i++)
{
for(int j=0;j<N;j++)
{
cout<<matrix1[i][j]<<" ";
}
cout<<endl;
}
cout<<endl;
for(int i=0;i<N;i++)
{
for(int j=0;j<N;j++)
{
cout<<matrix2[i][j]<<" ";
}
cout<<endl;
}
cout<<endl;
int i2, j2, k2;
double* rres, *rm1, *rm2;
for (int i = 0; i < N; i += SM)
for (int j = 0; j < N; j += SM)
for (int k = 0; k < N; k += SM)
for (i2 = 0, rres = &res3[i][j], rm1 = &matrix1[i][k]; i2 < SM; ++i2, rres +=N, rm1 += N)
for (k2 = 0, rm2 = &matrix2[k][j]; k2 < SM; ++k2, rm2 += N)
for (j2 = 0; j2 < SM; ++j2)
rres[j2] += rm1[k2] * rm2[j2];
for(int i=0;i<N;i++)
{
for(int j=0;j<N;j++)
{
cout<<res3[i][j]<<" ";
}
cout<<endl;
}
return 0;
}
 [/quote]
你应该没搞对,给下你完整代码[/quote]
[/quote]
你应该没搞对,给下你完整代码[/quote]
#include <vector>
#include <iostream>
using namespace std;
#define CACHE_LINE_SIZE 64
#define SM (CACHE_LINE_SIZE / sizeof(double))
int main()
{
double matrix1[5][5];
double matrix2[5][5];
double res3[5][5];
//initialize
for(int i=0;i<5;i++)
{
for(int j=0;j<5;j++)
{
matrix1[i][j] = i*j;
matrix2[i][j] = i*j;
}
}
for(int i=0;i<5;i++)
{
for(int j=0;j<5;j++)
{
cout<<matrix1[i][j]<<" ";
}
cout<<endl;
}
cout<<endl;
for(int i=0;i<5;i++)
{
for(int j=0;j<5;j++)
{
cout<<matrix2[i][j]<<" ";
}
cout<<endl;
}
cout<<endl;
int N=5;
int i2, j2, k2;
double* rres, *rm1, *rm2;
for (int i = 0; i < N; i += SM)
for (int j = 0; j < N; j += SM)
for (int k = 0; k < N; k += SM)
for (i2 = 0, rres = &res3[i][j], rm1 = &matrix1[i][k]; i2 < SM; ++i2, rres +=N, rm1 += N)
for (k2 = 0, rm2 = &matrix2[k][j]; k2 < SM; ++k2, rm2 += N)
for (j2 = 0; j2 < SM; ++j2)
rres[j2] += rm1[k2] * rm2[j2];
for(int i=0;i<5;i++)
{
for(int j=0;j<5;j++)
{
cout<<res3[i][j]<<" ";
}
cout<<endl;
}
return 0;
}
#include <vector>
#include <iostream>
using namespace std;
#define CACHE_LINE_SIZE 64
#define SM (CACHE_LINE_SIZE / sizeof(double))
int main()
{
double matrix1[5][5];
double matrix2[5][5];
double res3[5][5];
//initialize
for(int i=0;i<5;i++)
{
for(int j=0;j<5;j++)
{
matrix1[i][j] = i*j;
matrix2[i][j] = i*j;
}
}
for(int i=0;i<5;i++)
{
for(int j=0;j<5;j++)
{
cout<<matrix1[i][j]<<" ";
}
cout<<endl;
}
cout<<endl;
for(int i=0;i<5;i++)
{
for(int j=0;j<5;j++)
{
cout<<matrix2[i][j]<<" ";
}
cout<<endl;
}
cout<<endl;
int N=5;
int i2, j2, k2;
double* rres, *rm1, *rm2;
for (int i = 0; i < N; i += SM)
for (int j = 0; j < N; j += SM)
for (int k = 0; k < N; k += SM)
for (i2 = 0, rres = &res3[i][j], rm1 = &matrix1[i][k]; i2 < SM; ++i2, rres +=N, rm1 += N)
for (k2 = 0, rm2 = &matrix2[k][j]; k2 < SM; ++k2, rm2 += N)
for (j2 = 0; j2 < SM; ++j2)
rres[j2] += rm1[k2] * rm2[j2];
for(int i=0;i<5;i++)
{
for(int j=0;j<5;j++)
{
cout<<res3[i][j]<<" ";
}
cout<<endl;
}
return 0;
}
#include <vector>
#include <iostream>
using namespace std;
#define CACHE_LINE_SIZE 64
#define SM (CACHE_LINE_SIZE / sizeof(double))
#define N 8
int main()
{
double matrix1[N][N];
double matrix2[N][N];
double res3[N][N]={0};
//initialize
for(int i=0;i<N;i++)
{
for(int j=0;j<N;j++)
{
matrix1[i][j] = i*j;
matrix2[i][j] = i*j;
}
}
for(int i=0;i<N;i++)
{
for(int j=0;j<N;j++)
{
cout<<matrix1[i][j]<<" ";
}
cout<<endl;
}
cout<<endl;
for(int i=0;i<N;i++)
{
for(int j=0;j<N;j++)
{
cout<<matrix2[i][j]<<" ";
}
cout<<endl;
}
cout<<endl;
int i2, j2, k2;
double* rres, *rm1, *rm2;
for (int i = 0; i < N; i += SM)
for (int j = 0; j < N; j += SM)
for (int k = 0; k < N; k += SM)
for (i2 = 0, rres = &res3[i][j], rm1 = &matrix1[i][k]; i2 < SM; ++i2, rres +=N, rm1 += N)
for (k2 = 0, rm2 = &matrix2[k][j]; k2 < SM; ++k2, rm2 += N)
for (j2 = 0; j2 < SM; ++j2)
rres[j2] += rm1[k2] * rm2[j2];
for(int i=0;i<N;i++)
{
for(int j=0;j<N;j++)
{
cout<<res3[i][j]<<" ";
}
cout<<endl;
}
return 0;
}
#include <vector>
#include <iostream>
using namespace std;
#define CACHE_LINE_SIZE 64
#define SM (CACHE_LINE_SIZE / sizeof(double))
int main()
{
double matrix1[5][5];
double matrix2[5][5];
double res3[5][5];
//initialize
for(int i=0;i<5;i++)
{
for(int j=0;j<5;j++)
{
matrix1[i][j] = i*j;
matrix2[i][j] = i*j;
}
}
for(int i=0;i<5;i++)
{
for(int j=0;j<5;j++)
{
cout<<matrix1[i][j]<<" ";
}
cout<<endl;
}
cout<<endl;
for(int i=0;i<5;i++)
{
for(int j=0;j<5;j++)
{
cout<<matrix2[i][j]<<" ";
}
cout<<endl;
}
cout<<endl;
int N=5;
int i2, j2, k2;
double* rres, *rm1, *rm2;
for (int i = 0; i < N; i += SM)
for (int j = 0; j < N; j += SM)
for (int k = 0; k < N; k += SM)
for (i2 = 0, rres = &res3[i][j], rm1 = &matrix1[i][k]; i2 < SM; ++i2, rres +=N, rm1 += N)
for (k2 = 0, rm2 = &matrix2[k][j]; k2 < SM; ++k2, rm2 += N)
for (j2 = 0; j2 < SM; ++j2)
rres[j2] += rm1[k2] * rm2[j2];
for(int i=0;i<5;i++)
{
for(int j=0;j<5;j++)
{
cout<<res3[i][j]<<" ";
}
cout<<endl;
}
return 0;
}
for(int i = 0; i < nrows; i += SM) {
for(int j = 0; j < ncols; j += SM) {
for(int ii = 0; ii < SM; ii++) {
for(int jj = 0; jj < SM; jj++) {
diag[i + ii] += a[i + ii][j + jj] * b[j + jj][i + ii];
}
}
}
}
