[quote=引用 8 楼 closurer 的回复:]
[quote=引用 1 楼 closurer 的回复:] 我经常做爬虫,请楼主善待爬虫。
我经常做爬虫,请楼主善待爬虫。
只是为了防止数据被拿走的。。。有些数据是机密数据没办法阿
[quote=引用 2 楼 shiloye 的回复:] [quote=引用 1 楼 closurer 的回复:] 我经常做爬虫,请楼主善待爬虫。
62,269
社区成员
668,981
社区内容
加载中
.NET 社区是一个围绕开源 .NET 的开放、热情、创新、包容的技术社区。社区致力于为广大 .NET 爱好者提供一个良好的知识共享、协同互助的 .NET 技术交流环境。我们尊重不同意见,支持健康理性的辩论和互动,反对歧视和攻击。
希望和大家一起共同营造一个活跃、友好的社区氛围。
试试用AI创作助手写篇文章吧



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
 [/quote]
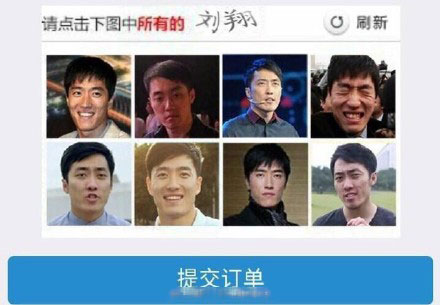
那么问题又来了,除了刘翔其他的是谁....
[/quote]
那么问题又来了,除了刘翔其他的是谁....