社区
脚本语言
帖子详情
python 操作mongodb 后回显数据html页面没有显示
Ycshmily_俊
2016-12-28 10:41:28
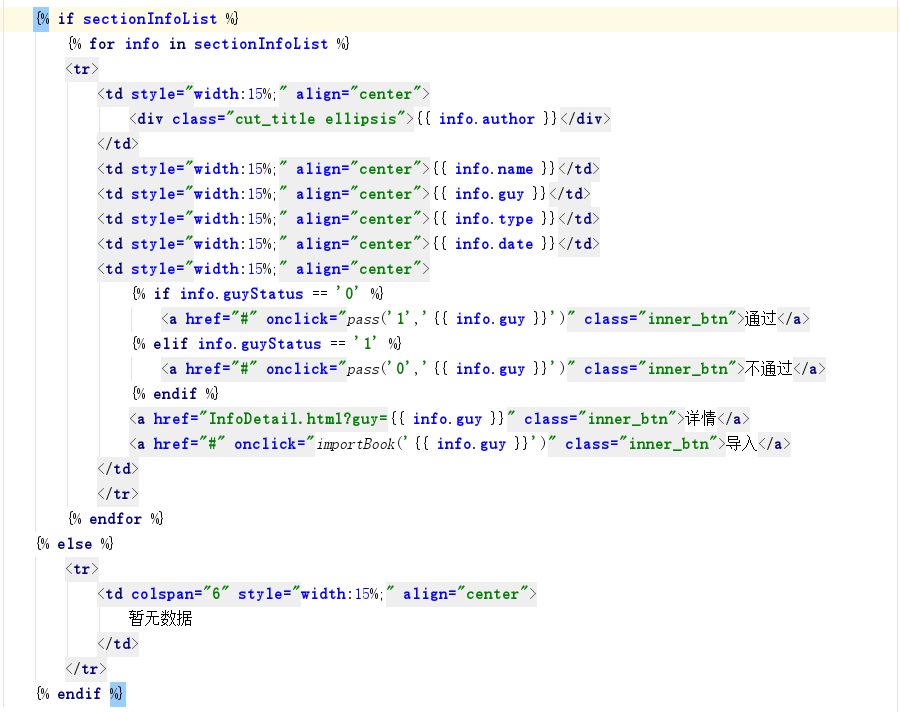
在用python语言开发中,做了一个搜索框像百度一样的,点击搜索后mongodb数据库有数据,一开始查找全部显示出所有数据是没有任何问题的,但是输入框搜索后查找的结果再返回到该页面的时候却没有回显,显示的还是全部的数据。使用{{}}遍历是可以的,但是就是没有显示出来,怎么回事?sectionInfoList 是数据库所有的数据,遍历出来没有问题。guyList 是查询关键字搜索出来的结果,回显不行!!!求解答,谢谢!!!
...全文
364
5
打赏
收藏
python 操作mongodb 后回显数据html页面没有显示
在用python语言开发中,做了一个搜索框像百度一样的,点击搜索后mongodb数据库有数据,一开始查找全部显示出所有数据是没有任何问题的,但是输入框搜索后查找的结果再返回到该页面的时候却没有回显,显示的还是全部的数据。使用{{}}遍历是可以的,但是就是没有显示出来,怎么回事?sectionInfoList 是数据库所有的数据,遍历出来没有问题。guyList 是查询关键字搜索出来的结果,回显不行!!!求解答,谢谢!!!
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
5 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
sss650216
2019-05-13
打赏
举报
回复
Ycshmily_俊
2016-12-28
打赏
举报
回复
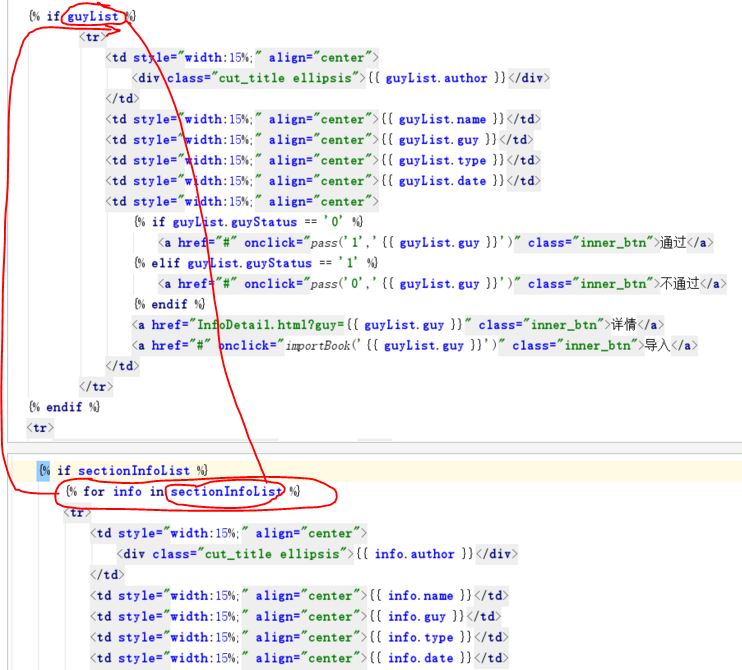
看不懂,为什么要把那一句搬上去呢?guyList只有一条数据,不用for循环就可以了呀
混沌鳄鱼
2016-12-28
打赏
举报
回复
Ycshmily_俊
2016-12-28
打赏
举报
回复
“只要把 guy 一条放在sectionInfoList 里面”这句不懂啊,求大神解释解释 print guy 能获取到值, print guyList 也能查出来值,并且结果如下: {u'name': u'\u6c82\u8499', u'guyStatus': u'0', u'author': u'\u8ff7\u9014\u5c0f\u4e66\u7ae5', u'date': u'2015-02-03', u'guy': u'\u661f\u8fb0\u53d8', u'_id': ObjectId('585c8f306d7fce38f1fa9efc'), u'type': u'\u7384\u5e7b'}
混沌鳄鱼
2016-12-28
打赏
举报
回复
你这个模板页不符合DRY原则啊,明显和下面是一样的显示模板啊。只要把 guy 一条放在sectionInfoList 里面。 你在findByGuy()里面 print guy 然后 print guyList 看看从数据库里取没取到数据
monquey:否}}});
MongoDB
Shell语法
独有的 否}}});
MongoDB
Shell语法 依存关系 cabal install regex-posix pip install termcolor (用于测试) 用法 制作
回显
“一些查询” ./monquey 测验
python
test.py 句法特征 用管道分隔的参数 分号分隔的数组 非包围物 键值对不包含“:” 支持比较运算符标识符 单例对象扩展(例如, abc 1变成a: {b: {c: 1}} ) =>运算符吸收所有内容,直到下一个分隔符成为对象 例子 创造 db people insert | name "Julian", age 19 db.people.insert({"name": "Julian", "age": 19}); db people insert | age 19, name => first "Julian", last "Rose
MongoDB
笔记
基本
操作
MongoDB
将
数据
存储为一个文档,
数据
结构由键值(key=>value)对组成
MongoDB
文档类似于JSON对象,字段值可以包含其他文档、数组、文档数组 SQL术语/概念
MongoDB
术语/概念 解释/说明 database database
数据
库 table collection
数据
库表/集合
基于Django框架对
MongoDB
实现增删改查
在上一篇中,咱们已经实现了Scrapy框架爬取
数据
,并且存储到
Mongodb
数据
库, 接下来呢,,,,,,,,,,,,, 咱们就要对这些
数据
进行
操作
。 目标:从
Mongodb
数据
库取出
数据
,通过Django框架展示到web
页面
,实现展示、分页、添加、修改、删除的功能 1. 准备工作 创建django项目 点击:file–>new project,出现下面的对话框。 选择Dj...
Python
-玩转
数据
-爬虫的基本原理
Python
-玩转
数据
-爬虫基本原理 一、说明: 网络爬虫,又名网页蜘蛛或网络机器人,是请求网站并提取
数据
的自动化程序,爬虫程序只提取网页代码中对我们有用的
数据
。 二、爬虫基本流程一般分四步 1、发起请求:用程序模拟浏览器通过HTTP库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,等待服务器响应。 2、获取响应内容:如果服务器能正常响应,会得到一个Response,Response的内容便是所要获取的
页面
内容,类型可能有
HTML
,Json字符串,二进制
数据
(如图片视频
Python
网络爬虫与
数据
采集(一)
Python
网络爬虫与
数据
采集第1章 序章 网络爬虫基础1 爬虫基本概述1.1 爬虫是什么1.2 爬虫可以做什么1.3 爬虫的分类1.4 爬虫的基本流程1.4.1 浏览网页的流程1.4.2 爬虫的基本流程1.5 爬虫与反爬虫1.5.1 爬虫的攻与防1.5.2 常见的反爬与反反爬1.6 爬虫的合法性与 robots 协议1.6.1 robots 协议1.6.2 查看网页的 robots 协议1.7
Python
爬虫相关库2. Chrome 浏览器开发者工具2.1 Chrome 浏览器开发者工具简述2.1
脚本语言
37,719
社区成员
34,239
社区内容
发帖
与我相关
我的任务
脚本语言
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
复制链接
扫一扫
分享
社区描述
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享