社区
Web 开发
帖子详情
如何使用爬虫技术(Jsoup)提取页面准确数据?
qq_37399847
2017-01-23 02:10:53
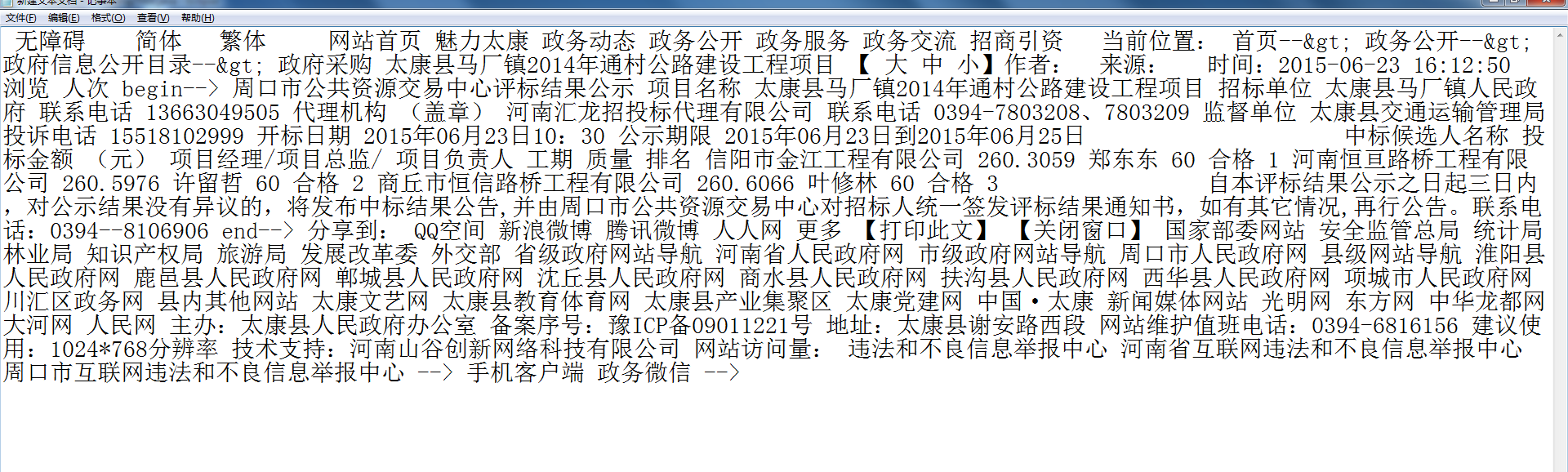
如上图;
想要获取:
项目名称 太康县马厂镇2014年通村公路建设工程项目
招标单位 太康县马厂镇人民政府
中标候选人名称 信阳市金江工程有限公司 1 河南恒亘路桥工程有限公司 2 商丘市恒信路桥工程有限公司
项目经理/项目总监/ 项目负责人 郑东东 许留哲 叶修林
获取之后保存到数据库
请大神帮忙给个方法
...全文
540
4
打赏
收藏
如何使用爬虫技术(Jsoup)提取页面准确数据?
如上图; 想要获取: 项目名称 太康县马厂镇2014年通村公路建设工程项目 招标单位 太康县马厂镇人民政府 中标候选人名称 信阳市金江工程有限公司 1 河南恒亘路桥工程有限公司 2 商丘市恒信路桥工程有限公司 项目经理/项目总监/ 项目负责人 郑东东 许留哲 叶修林 获取之后保存到数据库 请大神帮忙给个方法
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
4 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
showhunter74
2017-02-04
打赏
举报
回复
你打印结果的时候,可以不用text(),用html()。这样获取的就是带Html标签的字符串。然后用jsoup.parse(string),就能把页面转成document元素了。然后你想怎么整都可以了。各种根据id获取,class获取,tab获取都行。
weare微儿
2017-02-04
打赏
举报
回复
http://www.weare.net.cn/article/469f3b4da4de2df55ded7f0d1264160e.html
或许对你有帮助
可爱的小莱
2017-01-29
打赏
举报
回复
使用python,python擅长爬虫工作。
12312312312wwqeqw
2017-01-25
打赏
举报
回复
java+如何解决反
爬虫
_反
爬虫
,到底是怎么回事儿?
」这是个好问题,自从 Python 火了起来,编写
爬虫
程序的门口越来越低,爬取别人网站
数据
也越来越猖獗。阻止
爬虫
也就是我们这次要说的「反
爬虫
」,「反
爬虫
」涉及到的
技术
比较综合,说简单也简单,说复杂也复杂,看...
java毕业设计——基于java+
Jsoup
+HttpClient的网络
爬虫
技术
的网络新闻分析系统设计与实现(毕业论文+程序源码)——网络新闻分析系统
大家好,今天给大家介绍基于java+
Jsoup
+HttpClient的网络
爬虫
技术
的网络新闻分析系统设计与实现,文章末尾附有本毕业设计的论文和源码下载地址哦。文章目录: 项目难度:中等难度 适用场景:相关题目的毕业设计 配套...
使用
HttpClient和
Jsoup
定向抓取
数据
1.业务需求:从指定外网抓点货,冷启动2.站点分析:.限制IP… .需要登录…… .....抓取频率过低,直接跳验证码
页面
…………......验证码长度、模样(纯数字&字母数字混合)TM不固定……………….....3.
使用
技术
:1
在 Java 中,可以
使用
各种库和框架来实现
爬虫
功能,比如
Jsoup
、HttpClient、HttpClient4等
在这个示例中,我们首先
使用
Jsoup
的 `connect()` 方法发送 HTTP 请求并获取 HTML
页面
内容,然后
使用
CSS 选择器来选择标题元素,并
使用
`text()` 方法获取标题文本内容。需要注意的是,
爬虫
需要遵守网站的robots....
为啥现在很多
爬虫
工程师都不做
爬虫
了?
采集、分析和融合非隐私公开
数据
有利于行业发展、
数据
要素流通和
技术
进步。根据 Opimas Research 报告,全球网页挖掘和融合的市场规模大约每年 100 亿美金,其中外部采购支出大约每年20亿美金,并且以每年超过70% 的...
Web 开发
81,092
社区成员
341,716
社区内容
发帖
与我相关
我的任务
Web 开发
Java Web 开发
复制链接
扫一扫
分享
社区描述
Java Web 开发
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



