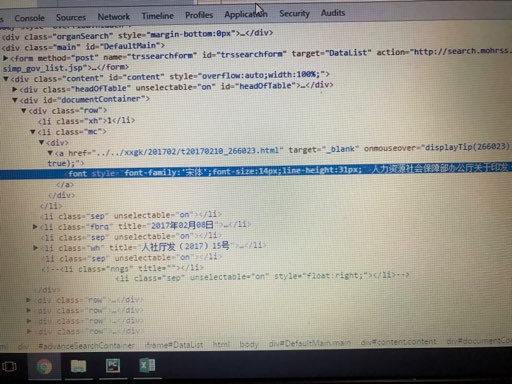
litle = soup.select(“a > font”) print(title) 你这打印的是title 不是litle。 返回 [] 的原因:页面不存在这样标签, 选择器代码(“a > font”)写错
37,719
社区成员
34,239
社区内容
加载中
试试用AI创作助手写篇文章吧



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



