社区
脚本语言
帖子详情
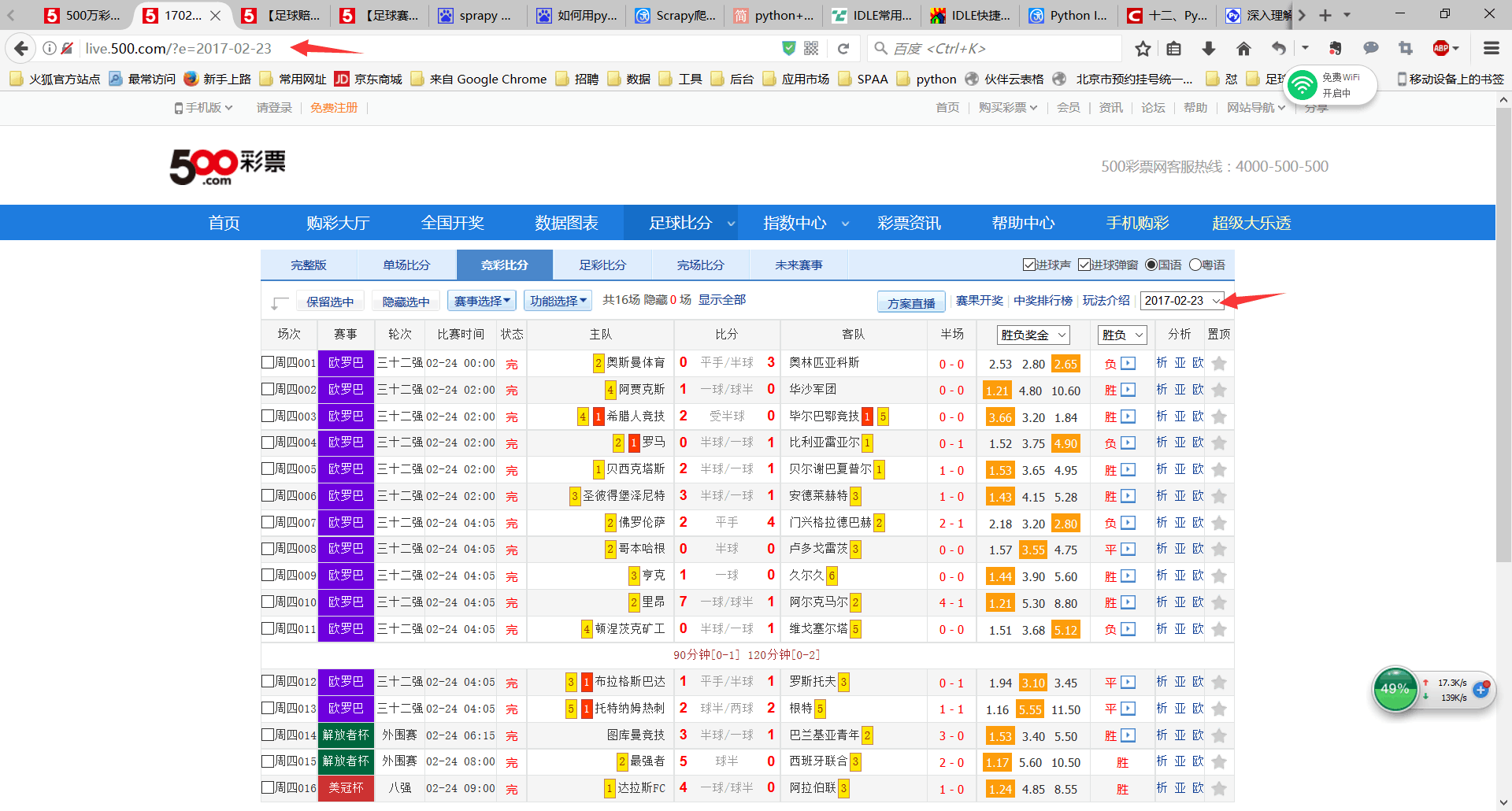
scrapy 爬虫如何实现按日期翻页
cixingzhici
2017-02-25 11:09:20
通过学习网上的抓豆瓣教程,已经能够实现基础的抓取功能,现在想实现上图的通过日期的翻页自动爬虫,求指教
...全文
196
回复
打赏
收藏
scrapy 爬虫如何实现按日期翻页
通过学习网上的抓豆瓣教程,已经能够实现基础的抓取功能,现在想实现上图的通过日期的翻页自动爬虫,求指教
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
[Python
Scrapy
爬虫
] 二.
翻页
爬取农产品信息并保存本地
前面 "Python
爬虫
之Selenium+Phantomjs+CasperJS" 介绍了很多Selenium基于自动测试的Python
爬虫
程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作。但是,更为广泛使用的Python
爬虫
框架是——
Scrapy
爬虫
。这篇文章是一篇基础文章,主要内容包括: 1.
Scrapy
爬...
Scrapy
-
爬虫
模板的使用
Scrapy
,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。
Scrapy
用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy
吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型
爬虫
的基类,如BaseSpider、sitemap
爬虫
等,最新版本又提供了web2.0
爬虫
的支持。在之前的博文中讲到,可以使用来查看
Scrapy
当前可用的
爬虫
模板,并且已知现在可用的
爬虫
模板有basicxmlfeedcsvfeed和。
scrapy
爬虫
进阶案例--爬取前程无忧招聘信息
上一次我们进行了
scrapy
的入门案例讲解,相信大家对此也有了一定的了解,详见新手入门的
Scrapy
爬虫
操作–超详细案例带你入门。接下来我们再来一个案例来对
scrapy
操作进行巩固。 一、爬取的网站 这里我选择的是杭州数据分析的岗位,网址如下:https://search.51job.com/list/080200,000000,0000,32,9,99,%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590,2,1.html?lang=c&
34.
scrapy
解决
爬虫
翻页
问题
34.
scrapy
解决
爬虫
翻页
问题 这里主要解决的问题:1.
翻页
需要找到页面中加载的两个参数。 '__VIEWSTATE': '{}'.format(response.meta['data']['__VIEWSTATE']), '__EVENTVALIDATION': '{}'.format(response.meta['dat...
Python
Scrapy
爬虫
框架爬取51job职位信息并保存至数据库
Python
Scrapy
爬虫
框架爬取51job职位信息并保存至数据库 ———————————————————————————————— 版权声明:本文为CSDN博主「杠精运动员」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 项目要求 使用
Scrapy
爬虫
框架练习爬取51Job网站招聘职位信息并保存至数据库(已sqlite3为例)。 工具软件 python == 3.7 pycharm == 20.2.3 sqlite == 3.33.0
scrapy
== 2.4
脚本语言
37,720
社区成员
34,239
社区内容
发帖
与我相关
我的任务
脚本语言
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
复制链接
扫一扫
分享
社区描述
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享