社区
脚本语言
帖子详情
用selenium和webdriver爬网页得到的html是unicode的格式
lukeyyanghang
2017-02-28 04:02:17
我得到了完整的html,我该如何爬取想要的数据
...全文
443
2
打赏
收藏
用selenium和webdriver爬网页得到的html是unicode的格式
我得到了完整的html,我该如何爬取想要的数据
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
2 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
Haisen's
2019-03-10
打赏
举报
回复
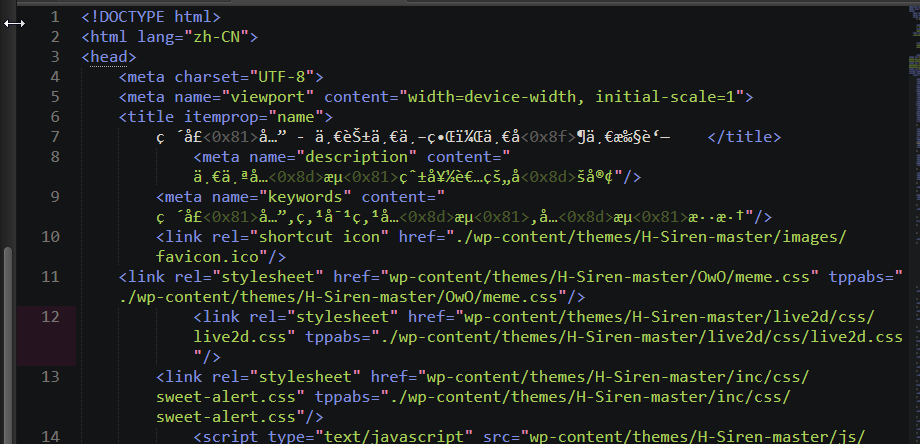
你没理解楼主意思,是这个扒取的网页设置的是 UTF-8 但是里面的内容是 乱码文字,坚定为Unicode字符,浏览器测试是他。但是源文件打开还是乱码文字 ,这个怎么结解决,我在想怎样修改文件编码格式为 Unicode
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title itemprop="name">
ç ´å£å…” - 一花一丼Œä¸€å¶ä¸€æ‰§è‘— </title>
<meta name="description" content="一个å…æµçˆ±å¥½è€…çš„åšå®¢"/>
<meta name="keywords" content="ç ´å£å…”,点对点å…æµ,å…æµæ··æ·†"/>
<link rel="shortcut icon" href="./wp-content/themes/H-Siren-master/images/favicon.ico"/>
<link rel="stylesheet" href="wp-content/themes/H-Siren-master/OwO/meme.css" tppabs="./wp-content/themes/H-Siren-master/OwO/meme.css"/>
secsilm
2017-03-01
打赏
举报
回复
这个你得问题描述的很模糊,你可以给出个html例子和你想要的数据。 但是总体上就是根据 tag 和 CSS 来定位和抽取你要的数据。可以使用
BeautifulSoup
包。
python如何实现图片压缩
本工具是通过将图片上传到第三方网站tinypng,进行压缩后下载,覆盖本地图片,tinypng是一个强大的图片处理网站,目前最可靠的无损压缩网站。 代码如下: import requests from idna import
unicode
from
selenium
import
webdriver
import time import os browser =
webdriver
.Firefox(executable_path='/Users/lyf/Library/Google/geckodriver') def tiny_png(url): # browser.get('http
Selenium
屏蔽
webdriver
被识别出来 的一些解决办法
问题描述 使用
selenium
模拟浏览器进行数据抓取是目前最通用的
爬
虫方案,所见即所得。通吃各种数据加载方式,能绕过JS加密、
爬
虫检测、签名机制。 但是
Selenium
依然能被检测到,它在运行时会暴露出一些预定义的JavaScript变量(特征字符串),如"window.navigator.
webdriver
",在非
Selenium
环境下为undefined,在
Selenium
环境下为true 检测
Selenium
检测
Selenium
的 JavaScript 代码
webdriver
= win
Selenium
3 Python
WebDriver
API源码探析(2):
Selenium
包目录结构、模块功能概述
Selenium
包结构概述
Selenium
包结构如下:
selenium
├─common └─
webdriver
├─android ├─blackberry ├─chrome ├─common │ ├─actions │ └─
html
5 ├─edge ├─firefox ├─ie ├─opera ├─phantomjs ├─remote ├─safari ├─support
总结
Selenium
WebDriver
中一些鼠标和键盘事件的使用
在使用
Selenium
WebDriver
做自动化测试的时候,会经常模拟鼠标和键盘的一些行为。比如使用鼠标单击、双击、右击、拖拽等动作;或者键盘输入、快捷键使用、组合键使用等模拟键盘的操作。在 WebDeriver 中,有一个专门的类来负责实现这些测试场景,那就是 Actions 类,在使用该类的过程中会配合使用到 Keys 枚举以及 Mouse、 Keyboard、CompositeActi
Selenium
源码通读:
WebDriver
模块下的“keys.py“ - Keys类分析
在这篇文章中,我们将详细分析
Selenium
的
WebDriver
模块下的"keys.py"文件中的Keys类,这个类提供了一组常用键盘按键的常量。在本文中,我们对
Selenium
的
WebDriver
模块下的"keys.py"文件中的Keys类进行了详细分析。通过使用Keys类,我们可以方便地实现各种键盘操作,以满足自动化测试的需求。在这个源代码中,我们可以看到Keys类定义了许多静态变量,每个变量都代表一个常用的键盘按键。通过使用Keys类,我们可以很方便地模拟各种键盘操作,以满足自动化测试的需求。
脚本语言
37,719
社区成员
34,239
社区内容
发帖
与我相关
我的任务
脚本语言
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
复制链接
扫一扫
分享
社区描述
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
试试用AI创作助手写篇文章吧
+ 用AI写文章




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享