社区
Spark
帖子详情
spark streaming, kafka导入数据到es性能调优
WAVwind
2017-03-01 11:23:50
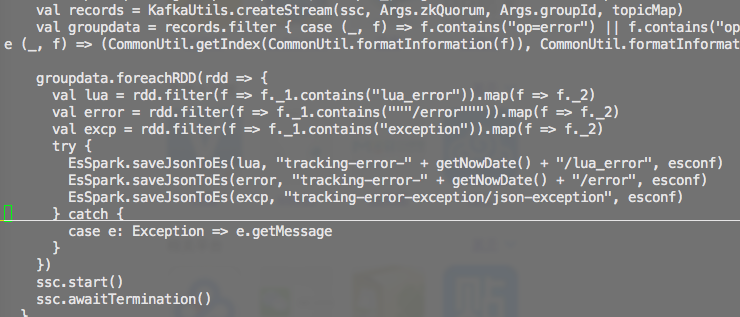
主要代码如图, 求教如何提升性能, 将kafka数据导入到es
...全文
865
2
打赏
收藏
spark streaming, kafka导入数据到es性能调优
主要代码如图, 求教如何提升性能, 将kafka数据导入到es
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
2 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
HelloWordSong
2018-10-10
打赏
举报
回复
pom依赖能发下吗?
LinkSe7en
2017-03-02
打赏
举报
回复
导入Es那块估计没什么好优化的。从Kafka接收数据那块可以优化。看看官方文档的KafkaUtils.createDirectStream
使用Flume+Logstash+
Kafka
+
Spark
Streaming
进行实时日志处理分析【大
数据
】
flume+Logstash+
Kafka
+
Spark
Streaming
进行实时日志处理分析【大
数据
】
spark
streaming
:封装
spark
streaming
动态调节batch time(有
数据
就执行计算); 支持运行过程中增删topic; 封装
spark
streaming
1.6 -
kafka
010 用以支持 SSL
:party_popper:v1.6.0-0.10 解决了批次计算延迟后出现的任务append导致整体恢复后 计算消费还是跟不上的问题 支持动态调节
streaming
的 批次间隔时间 (不同于
spark
streaming
的 定长的批次间隔,Structured
Streaming
中使用trigger实现了。) 支持在
streaming
过程中 重设 topics,用于生产中动态地增加删减
数据
源 添加了速率控制,
Kafka
RateController。用来控制读取速率,由于不是用的
spark
streaming
,所有速率控制的一些参数拿不到,得自己去计算。 提供
spark
-
streaming
-
kafka
-0-10_2.10
spark
1.6 来支持
kafka
的ssl 支持rdd.updateOffset 来管理偏移量。 :party_popper: v1.6.0-0.10_ssl 只是结合了
spark
streaming
1.6 和 ka
基于
spark
-
streaming
框架的实时计算系统源码+项目说明.zip
1.项目代码均经过功能验证ok,确保稳定可靠运行。欢迎下载体验!下载完使用问题请私信沟通。 2.主要针对各个计算机相关专业,包括计算机科学、信息安全、
数据
科学与大
数据
技术、人工智能、通信、物联网等领域的在校学生、专业教师、企业员工。 3.项目具有丰富的拓展空间,不仅可作为入门进阶,也可直接作为毕设、课程设计、大作业、初期项目立项演示等用途。 4.当然也鼓励大家基于此进行二次开发。在使用过程中,如有问题或建议,请及时沟通。 5.期待你能在项目中找到乐趣和灵感,也欢迎你的分享和反馈! 【资源说明】 基于
spark
-
streaming
框架的实时计算系统源码+项目说明.zip 项目架构: 开发语言:Scala、Java 计算框架:
Spark
-
Streaming
数据
库:Redis、Elasticsearch 消息队列:
Kafka
数据
采集:Maxwell(离线)、
Spark
-
Streaming
(实时)
数据
可视化:Spring-Boot、Echart 项目流程: 1、产生
数据
到MySQL; 2、使用Maxwell把
数据
从MySQL采集到
Kafka
; 3、ODS层
Spark
-
Streaming
从
Kafka
消费
数据
,对消费的
数据
进行分流处理,维度
数据
写入Redis,事实
数据
重新写入
Kafka
的不同主题; 4、DWD层
Spark
-
Streaming
再从相应的
Kafka
主题中消费
数据
,进行
数据
处理,写入到Elasticsearch; 5、通过Spring-Boot开发相关接口,从写入到Elasticsearch中读取
数据
并展示。 项目亮点: 解决从
Kafka
中消费
数据
时的漏消费、重复消费以及读取
数据
时的顺序问题。 publisher-realtime——
数据
可视化模块
spark
Streaming
-realtime——实时计算模块
stream-proc
es
sing-engine:这是使用
Spark
Streaming
,
Kafka
和Elasticsearch进行实时流处理的示例
流处理引擎 这是使用
Spark
Streaming
,
Kafka
和Elasticsearch进行近实时流处理的示例。 此项目的先决条件 Elasticsearch设置 i)Elasticsearch 6.3.0或最新版本并将其解压缩。 ii)运行以下命令。 $ bin/elasticsearch
Kafka
设置 i)
Kafka
-0.10.0.1或最新版本并解压缩。 ii)运行以下命令以启动Zookeeper和
Kafka
: $ bin/zookeeper-server-start.sh config/zookeeper.properti
es
$ bin/
kafka
-server-start.sh config/server.properti
es
入门: 克隆并以本地模式运行: $ git clone git@github.com:techmonad/st
数据
处理管道:使用Docker,
Spark
,
Kafka
和Cassandra进行实时
数据
处理管道和可视化
数据
处理管道 描述 只需5个步骤,即可使用Docker Machine和Compose,
Kafka
,Cassandra和
Spark
构建功能强大的实时
数据
处理管道和可视化解决方案。 参见下面的项目架构: 到底发生了什么事? 我们连接到twitter流API( ),并开始基于关键字列表侦听事件,这些事件直接转发到
Kafka
(不解析)。 在中间,有一个
spark
作业,收集这些事件,将它们转换为
Spark
SQL上下文( ),该上下文过滤
kafka
消息并仅提取感兴趣的字段,在这种情况下为: user.location,文本和user.profile_image_url ,一旦有了,我们就会使用
Spark
1,258
社区成员
1,168
社区内容
发帖
与我相关
我的任务
Spark
Spark由Scala写成,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于MapReduce算法实现的分布式计算。
复制链接
扫一扫
分享
社区描述
Spark由Scala写成,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于MapReduce算法实现的分布式计算。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


