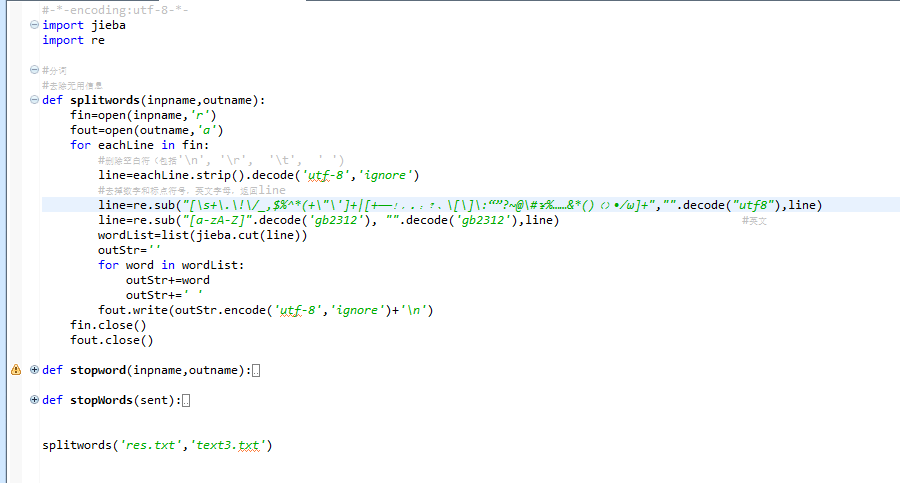
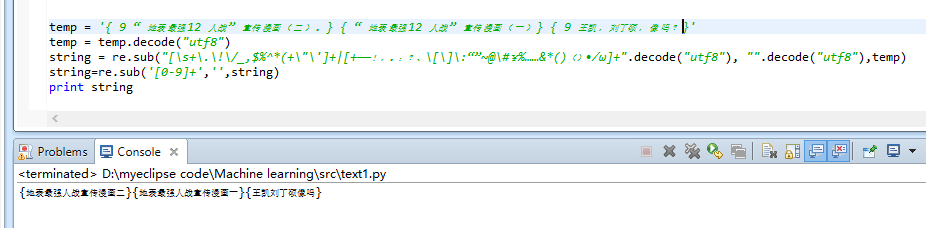
你在第一个图片里没有替换数字,但是注释里写了替换数字。
你把整个代码(函数splitwords)贴出来,我试试。[/quote]
这就是整个代码,处理数字的时候 只要把line=re.sub("[a-zA-Z0-9]".decode('utf-8'), "".decode('utf-8'),line) 这里改了就可以啊。
#-*-encoding:utf-8-*-
import jieba
import re
def splitwords(inpname,outname):
fin=open(inpname,'r')
fout=open(outname,'a')
stopwords = {}.fromkeys([ line.rstrip() for line in open('stopwords.txt')])
for eachLine in fin:
#删除空白符(包括'\n', '\r', '\t', ' ')
line=eachLine.strip().decode('utf-8','ignore')
#去掉数字和标点符号,英文字母,返回line
line=re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?、~:- :()“ ” ;《》【 】@#¥%……&*()]+".decode('gb2312'), "".decode('gb2312'),line)
line=re.sub("\[|]".decode('utf-8'), "".decode('utf-8'),line)
line=re.sub("[a-zA-Z0-9]".decode('utf-8'), "".decode('utf-8'),line) #英文
wordList=list(jieba.cut(line))
outStr=''
for word in wordList:
if word not in stopwords:
outStr+=word
outStr+=' '
fout.write(outStr.encode('utf-8','ignore')+'\n')
fin.close()
fout.close()
splitwords('r1.txt','result1.txt')


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享