最近在做Elasticearch的搜索测试,在字段里面设置了
[String(Index = FieldIndexOption.NotAnalyzed)]
public string Firstname { get; set; }
加了不分词,但是测试下来并没什么卵用,比如我的Firstname字段给他“”a abc d“”这样的字符串,中间有空格,他就会给我继续的分词,上图说话:
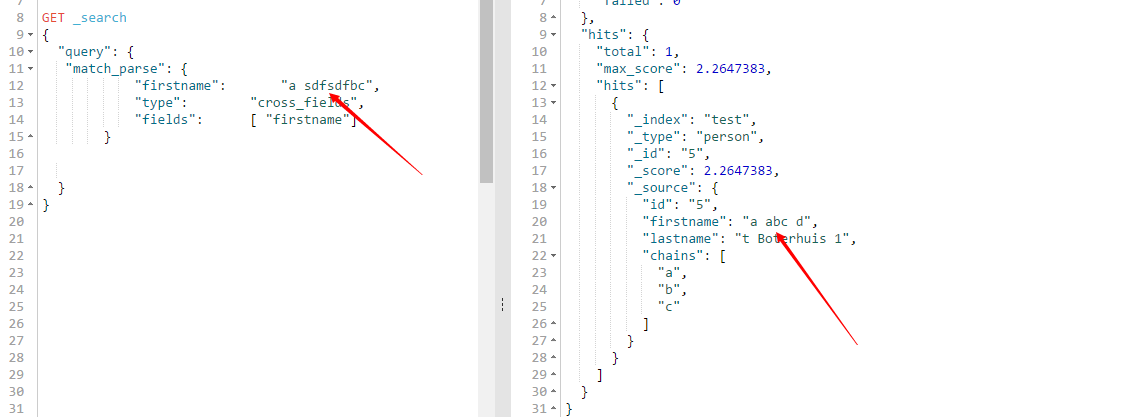
随便我输入什么,他还是显示出来了,所以还是进行了分词,想知道这个特性存在的意义是什么,我测试下来没发现他有什么价值



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享





