

34,875
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



SELECT *
FROM supply a
JOIN tree b ON a.treeId = b.treeId
JOIN ( SELECT supply.treeId ,
COUNT(1) AS num
FROM supply
JOIN tree ON supply.treeId = tree.treeId
GROUP BY supply.treeId
) t ON b.treeId = t.treeId
ORDER BY t.num DESC [/quote]
[/quote]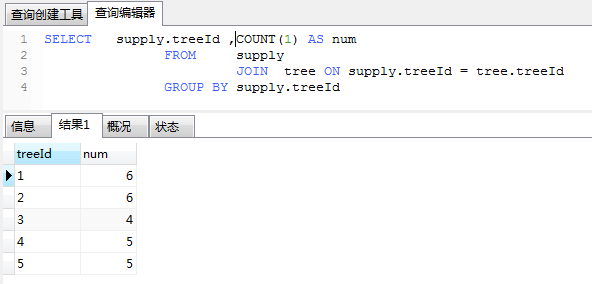
SELECT a.* ,
b.*
FROM supply a
JOIN tree b ON a.treeid = b.treeid
JOIN ( SELECT treename ,
COUNT(treename) AS num
FROM supply
JOIN tree ON supply.treeid = tree.treeid
GROUP BY treename
) t ON b.treename = t.treename
ORDER BY t.num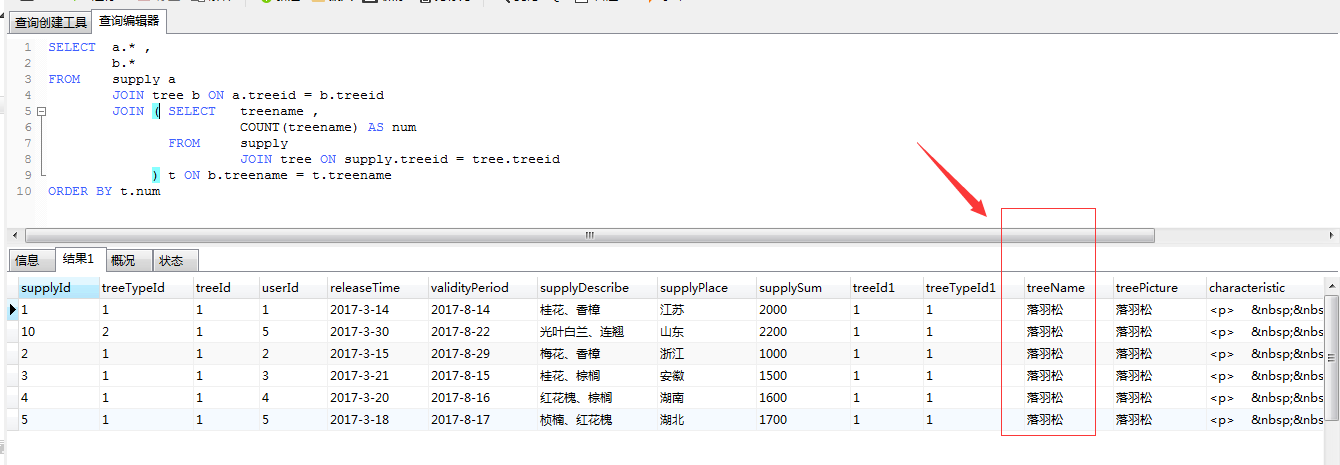
SELECT a.* ,
b.*
FROM supply a
JOIN tree b ON a.treeid = b.treeid
JOIN ( SELECT treename ,
COUNT(treename) AS num
FROM supply
JOIN tree ON supply.treeid = tree.treeid
) t ON b.treename = t.treename
ORDER BY t.num
SELECT *
FROM supply a
JOIN tree b ON a.treeId = b.treeId
JOIN ( SELECT supply.treeId ,
COUNT(1) AS num
FROM supply
JOIN tree ON supply.treeId = tree.treeId
GROUP BY supply.treeId
) t ON b.treeId = t.treeId
ORDER BY t.num DESCSELECT *
FROM supply a
JOIN tree b ON a.treeId = b.treeId
JOIN ( SELECT supply.treeId ,
COUNT(1) AS num
FROM supply
JOIN tree ON supply.treeId = tree.treeId
GROUP BY supply.treeId
) t ON b.treeId = t.treeId
ORDER BY t.num DESCSELECT *
FROM supply a
JOIN tree b ON a.treeId = b.treeId
JOIN ( SELECT supply.treeId ,
COUNT(1) AS num
FROM supply
JOIN tree ON supply.treeId = tree.treeId
GROUP BY supply.treeId
) t ON b.treeId = t.treeId
ORDER BY t.num DESC--测试数据
if not object_id(N'Tempdb..#supply') is null
drop table #supply
Go
Create table #supply([supplyid] int,[treeTypeID] int,[treeId] int,[userId] int,[releaseTIme] Date,[validityPeriod] Date,[supplyDescribe] nvarchar(27),[supplyPlace] nvarchar(22),[supplySum] int)
Insert #supply
select 1,1,1,1,'2017-3-14','2017-8-14',N'桂花、香樟',N'江苏',2000 union all
select 10,2,1,5,'2017-3-30','2017-8-22',N'光叶白兰、连翘',N'山东',2200 union all
select 11,3,2,1,'2017-3-31','2017-8-23',N'青桐、光叶白兰',N'天津',2300 union all
select 12,3,3,2,'2017-3-22','2017-8-24',N'枫杨、青桐',N'江西',2400 union all
select 13,3,3,3,'2017-3-24','2017-8-25',N'意杨、枫杨',N'福建',2500 union all
select 14,3,3,4,'2017-3-25','2017-8-26',N'丰花月季、意杨',N'四川',2600 union all
select 15,3,3,5,'2017-3-23','2017-8-27',N'红枫、丰花月季',N'重庆',2700 union all
select 16,4,4,1,'2017-3-19','2017-8-28',N'侧柏、红枫',N'北京',2800 union all
select 17,4,4,2,'2017-3-13','2017-8-29',N'竹柏、侧柏',N'江苏',2900 union all
select 18,4,4,3,'2017-3-26','2017-8-30',N'柳杉、竹柏',N'浙江',3000 union all
select 19,4,4,4,'2017-3-10','2017-8-13',N'国槐、柳杉',N'安徽',3100 union all
select 2,1,1,2,'2017-3-15','2017-8-29',N'梅花、香樟',N'浙江',1000 union all
select 20,4,4,5,'2017-3-11','2017-8-12',N'白蜡树、国槐',N'湖南',3200 union all
select 21,5,5,1,'2017-3-12','2017-8-11',N'落羽松、雪松',N'湖北',3300 union all
select 22,5,5,2,'2017-3-13','2017-8-10',N'雪松、国槐',N'上海',3400 union all
select 23,5,5,3,'2017-3-9','2017-8-9',N'罗汉松、白蜡树',N'河北',3500 union all
select 24,5,5,4,'2017-3-8','2017-8-8',N'木荷、罗汉松',N'河南',3500 union all
select 25,5,5,5,'2017-3-7','2017-8-7',N'樱花、木荷',N'海南',3000 union all
select 26,2,2,6,'2017-4-8','2017-9-8',N'连翘、法桐',N'江苏',10000 union all
select 3,1,1,3,'2017-3-21','2017-8-15',N'桂花、棕榈',N'安徽',1500 union all
select 4,1,1,4,'2017-3-20','2017-8-16',N'红花槐、棕榈',N'湖南',1600 union all
select 5,1,1,5,'2017-3-18','2017-8-17',N'桢楠、红花槐',N'湖北',1700 union all
select 6,2,2,1,'2017-3-17','2017-8-18',N'池杉、桢楠',N'上海',1800 union all
select 7,2,2,2,'2017-3-28','2017-8-19',N'木槿、海滨木槿',N'河北',1900 union all
select 8,2,2,3,'2017-3-27','2017-8-20',N'法桐、桢楠',N'河南',2000 union all
select 9,2,2,4,'2017-3-29','2017-8-21',N'连翘、法桐',N'山西',2100
GO
if not object_id(N'Tempdb..#tree') is null
drop table #tree
Go
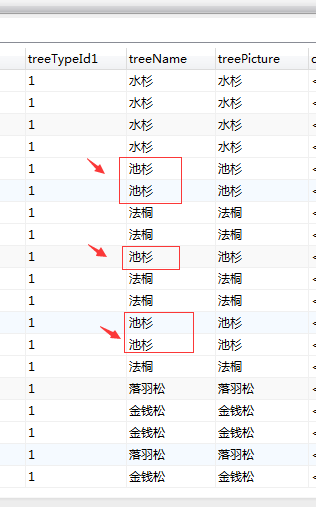
Create table #tree([treeId] int,[treeTypeId] int,[treeName] nvarchar(23))
Insert #tree
select 1,1,N'落羽松' union all
select 2,1,N'金钱松' union all
select 3,1,N'水杉' union all
select 4,1,N'池杉' union all
select 5,1,N'法桐'
Go
--测试数据结束
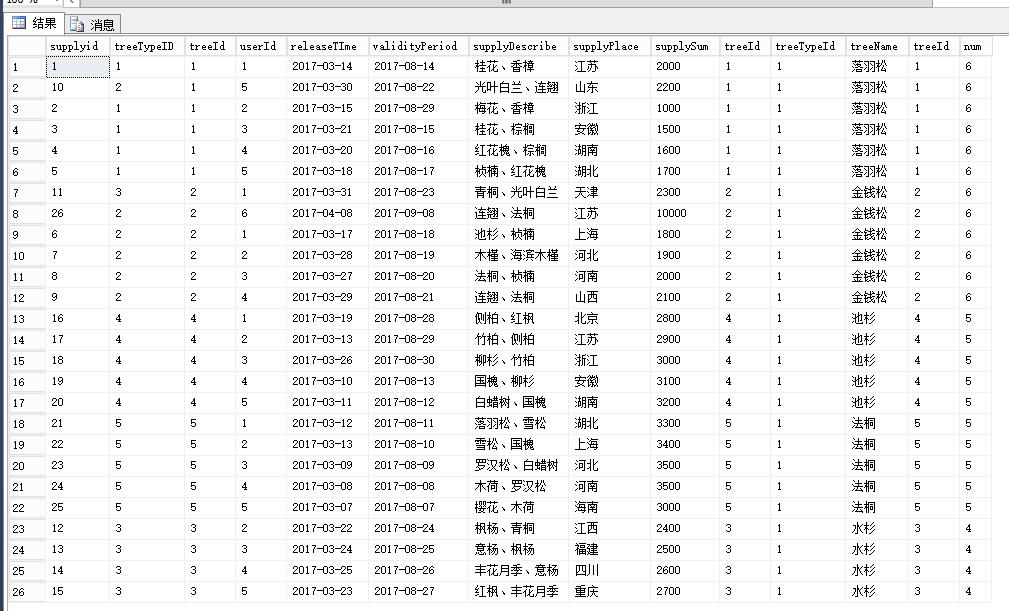
SELECT *
FROM #supply a
JOIN #tree b ON a.treeId = b.treeId
JOIN ( SELECT #supply.treeId ,
COUNT(1) AS num
FROM #supply
JOIN #tree ON #supply.treeId = #tree.treeId
GROUP BY #supply.treeId
) t ON b.treeId = t.treeId
ORDER BY t.num DESC
 [/quote]
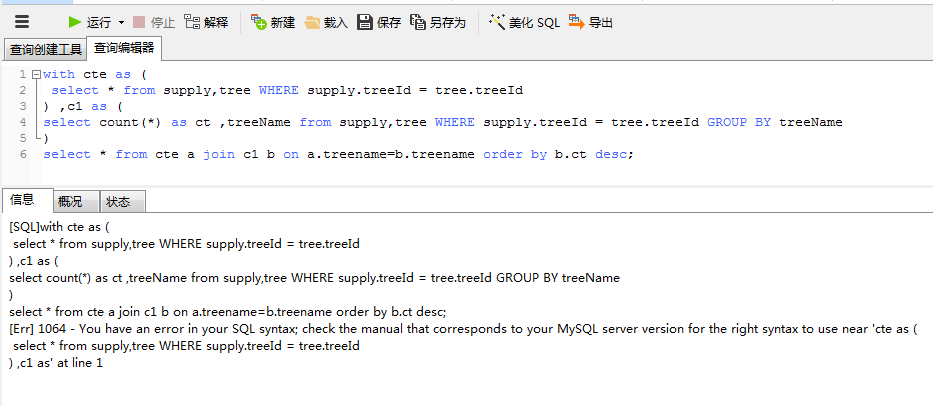
我这个是mssql 没注意看到你说的是mysql
,mysql应该可以用扩展表吧。你把 cte 和 c1 直接用两个()包起来
select * from (第一个查询) a join (第二个查询) b on a.treename=b.treename order by b.ct desc;
[/quote]
我这个是mssql 没注意看到你说的是mysql
,mysql应该可以用扩展表吧。你把 cte 和 c1 直接用两个()包起来
select * from (第一个查询) a join (第二个查询) b on a.treename=b.treename order by b.ct desc;


