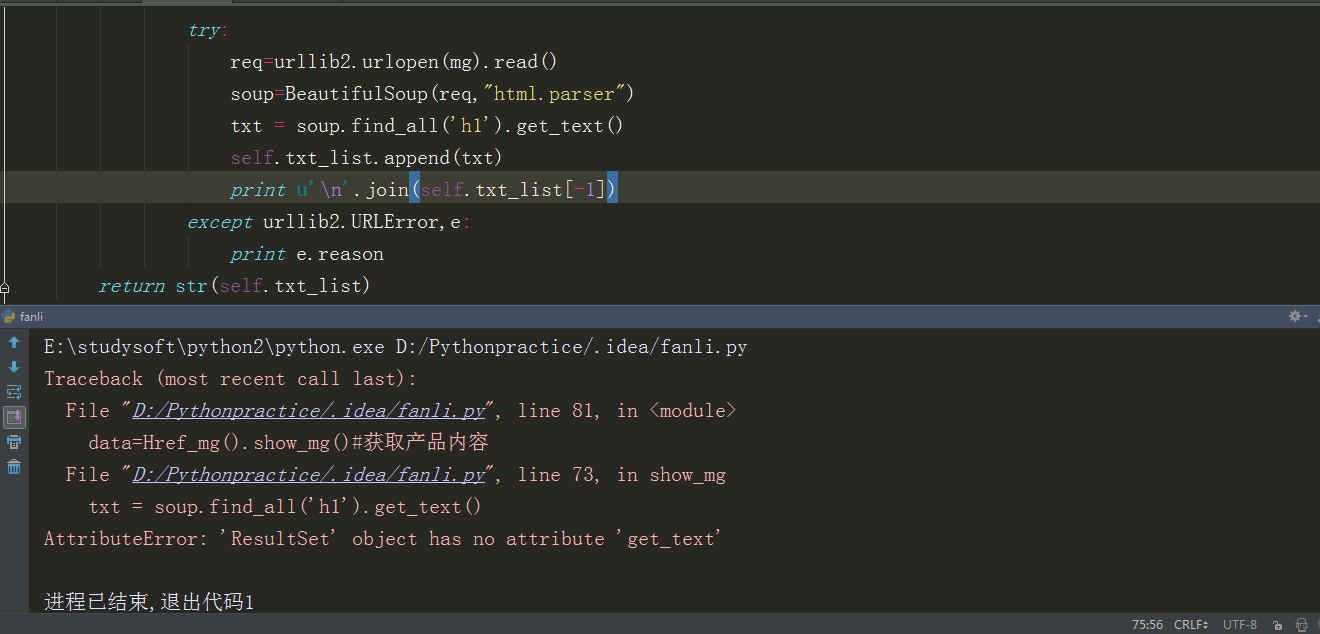
直接上码,描述: 本人小白想爬返利网的商品信息,获取完网页源码并且找到h1标题即商品信息的时候保存到一个数组里面,就在这时候,问题来了,获取的标题中文都是Unicode码,输出也为Unicode码,但是,,LZ想看到输出的是中文啊。请诸君指教。
#-*- coding:utf-8 -*-
import urllib2,re
from bs4 import BeautifulSoup
import time,socket
fanly_url="http://zhide.fanli.com/p"
format_url="http://zhide.fanli.com/detail/1-"
class Faly():
def __init__(self):#初始化构造函数,self=this本身
self.user_agent='Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0'#头部信息
self.html_data=[]#放置商品信息的列表
#获取主页的源码
def get_html(self,start_page=1,end_page=5):
for i in range(start_page,end_page+1):
rt=urllib2.Request(fanly_url+str(i))#用地址创建了一个Request对象
rt.add_header('User_Agent',self.user_agent)
try:
my_date=urllib2.urlopen(rt).read() #打开网页获取源码
#print my_date
self.html_data.append(my_date)
time.sleep(2)
socket.setdefaulttimeout(15)
except urllib2.URLError,e:
if hasattr(e,'reason'):#判断异常是否存在的一个函数
print u"connect wrong",e.reason
return str(self.html_data)
#html = Faly().get_html()
class GetData():
def __init__(self):
self.html=Faly().get_html()#获取源码
self.href=[]
self.ls=[]
self.url=[]
def get_hrefurl(self):
reg=r'data-id="\d{6}"'
result=re.compile(reg)#编译,提高效率
tag=result.findall(self.html)
#tag=re.findall(result,self.html)
# print tag
for i in tag:
self.href.append(i)
#print self.href
#去重
reg2=r"\d{6}"
result2=re.findall(reg2,str(self.href))
if len(result2):
for data in result2:
if data not in self.ls:
self.ls.append(data)
url=format_url+str(data)
self.url.append(url)
#print self.url
return self.url
a=GetData().get_hrefurl()
#获取产品信息
class Href_mg():
def __init__(self):
self.list=GetData().get_hrefurl()
self.txt_list=[]#商品信息列表
def show_mg(self):
for item in range(len(self.list)):
if len(self.list):
url =str(self.list[item])
mg=urllib2.Request(url)
try:
req=urllib2.urlopen(mg).read()
soup=BeautifulSoup(req,"html.parser")
txt=soup.find_all('h1')
self.txt_list.append(txt)
print self.txt_list
except urllib2.URLError,e:
print e.reason
return str(self.txt_list)
data=Href_mg().show_mg()#获取产品内容
输出内容如下(一部分)
E:\studysoft\python2\python.exe D:/Pythonpractice/.idea/fanli.py
[[<h1 class="zdm-detail-title bold ">\u4eac\u4e1c\u5546\u57ce \u808c\u6c34 \u808c\u80a4\u6ecb\u6da6\u9732 400ml *4\u4ef6 <span class="red">100\u5143\u5305\u90ae \xa0\xa0\u5df2\u964d100\u5143</span></h1>]]
[[<h1 class="zdm-detail-title bold ">\u4eac\u4e1c\u5546\u57ce \u808c\u6c34 \u808c\u80a4\u6ecb\u6da6\u9732 400ml *4\u4ef6 <span class="red">100\u5143\u5305\u90ae \xa0\xa0\u5df2\u964d100\u5143</span></h1>], [<h1 class="zdm-detail-title bold item-no-expired"><i class="record-low">\u5386\u53f2\u65b0\u4f4e</i>\u4eac\u4e1c\u5546\u57ce adidas\u963f\u8fea\u8fbe\u65af \u7537\u5973\u7ae5\u978b\u5a74\u7ae5\u8bad\u7ec3\u978b <span class="red">189\u5143\u5305\u90ae\xa0\xa0\u5df2\u964d100\u5143\uff0c\u9700\u7528\u5238</span></h1>]]
个人觉得问题主要在红色部分。



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享