

33,007
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

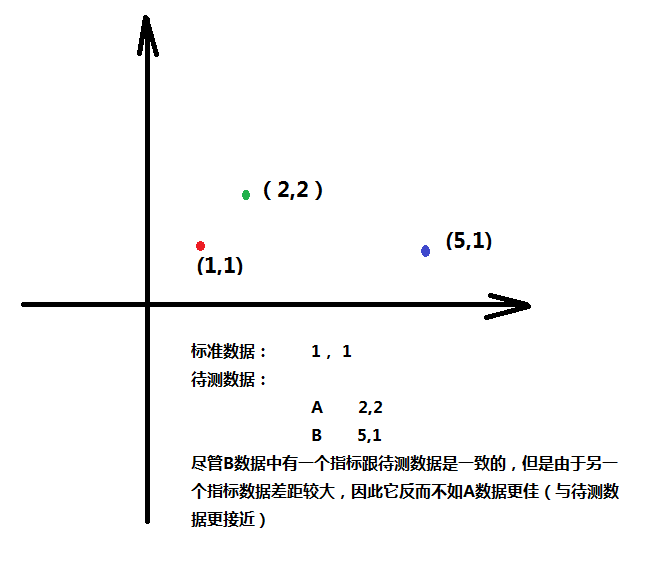
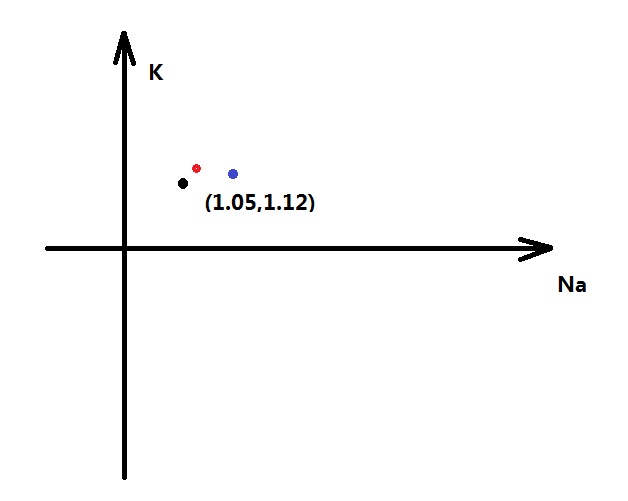 如上图所示,只考虑两种指标的情况下,假设一组数据是k 1.05,na 1.12,则如同图上黑点所描述。显然红色的点比蓝色点更接近黑点,就是距离更短,也就是更具相似性。
将两维空间扩展到m维即可。[/quote]
首先谢谢您的回复,看到您的回答,按照您的计算方法是只要比较距离的差值,即
√( 指标1所测的-指标1推荐的)平方+(指标2所测的-指标2推荐的)平方+...(指标m所测的-指标m推荐的)平方
最终看哪个更小即可对么?
但目前我关注的重点不是两组数据数的大小的相似性,而是关注我所测数据整体来看各部所占比例,与对比参考数据各指标所占比例的相似性,也就是说百分比相似性的对比。应该怎么说这个词,恩,就是哪个的组成和推荐更匹配?
比如,我目前看到的推荐是
K 2000 Na 1500 Ca 800 P 700 Mg 300 各元素比例是20:15:8:7:3
目前测出2种水果中含量(mg/100g)分别为
A : K 20 Na 15 Ca 8 P 7 Mg 3 各元素比例是20:15:8:7:3
B : K 250 Na 110 Ca 18 P 26 Mg 96 各元素比例是125 :55: 9 :13: 48
由此可见,虽然B的含量多,但A在比例的均衡性上更加接近推荐的比例,因此在这方面A更优
这只是在比例差异比较明显的情况下,在相差不是很明显比如我最开始提问举的例子中的数据,这时候有没有可能通过数学计算,得到一个最终的数据去比较?不知您的方法是否对我的问题可行。
还是谢谢了
[/quote]
只是把数据改成了比值而已,用比值当做坐标点其实还是一样的。[/quote]
您的意思是用比例的数据去比较么 还是说是否约到最简对它结果没有影响 ?
公式还是 √( 指标1所测的-指标1推荐的)平方+(指标2所测的-指标2推荐的)平方+...(指标m所测的-指标m推荐的)平方?代入数据还是原始数据?
如上图所示,只考虑两种指标的情况下,假设一组数据是k 1.05,na 1.12,则如同图上黑点所描述。显然红色的点比蓝色点更接近黑点,就是距离更短,也就是更具相似性。
将两维空间扩展到m维即可。[/quote]
首先谢谢您的回复,看到您的回答,按照您的计算方法是只要比较距离的差值,即
√( 指标1所测的-指标1推荐的)平方+(指标2所测的-指标2推荐的)平方+...(指标m所测的-指标m推荐的)平方
最终看哪个更小即可对么?
但目前我关注的重点不是两组数据数的大小的相似性,而是关注我所测数据整体来看各部所占比例,与对比参考数据各指标所占比例的相似性,也就是说百分比相似性的对比。应该怎么说这个词,恩,就是哪个的组成和推荐更匹配?
比如,我目前看到的推荐是
K 2000 Na 1500 Ca 800 P 700 Mg 300 各元素比例是20:15:8:7:3
目前测出2种水果中含量(mg/100g)分别为
A : K 20 Na 15 Ca 8 P 7 Mg 3 各元素比例是20:15:8:7:3
B : K 250 Na 110 Ca 18 P 26 Mg 96 各元素比例是125 :55: 9 :13: 48
由此可见,虽然B的含量多,但A在比例的均衡性上更加接近推荐的比例,因此在这方面A更优
这只是在比例差异比较明显的情况下,在相差不是很明显比如我最开始提问举的例子中的数据,这时候有没有可能通过数学计算,得到一个最终的数据去比较?不知您的方法是否对我的问题可行。
还是谢谢了
[/quote]
只是把数据改成了比值而已,用比值当做坐标点其实还是一样的。
如上图所示,只考虑两种指标的情况下,假设一组数据是k 1.05,na 1.12,则如同图上黑点所描述。显然红色的点比蓝色点更接近黑点,就是距离更短,也就是更具相似性。
将两维空间扩展到m维即可。[/quote]
首先谢谢您的回复,看到您的回答,按照您的计算方法是只要比较距离的差值,即
√( 指标1所测的-指标1推荐的)平方+(指标2所测的-指标2推荐的)平方+...(指标m所测的-指标m推荐的)平方
最终看哪个更小即可对么?
但目前我关注的重点不是两组数据数的大小的相似性,而是关注我所测数据整体来看各部所占比例,与对比参考数据各指标所占比例的相似性,也就是说百分比相似性的对比。应该怎么说这个词,恩,就是哪个的组成和推荐更匹配?
比如,我目前看到的推荐是
K 2000 Na 1500 Ca 800 P 700 Mg 300 各元素比例是20:15:8:7:3
目前测出2种水果中含量(mg/100g)分别为
A : K 20 Na 15 Ca 8 P 7 Mg 3 各元素比例是20:15:8:7:3
B : K 250 Na 110 Ca 18 P 26 Mg 96 各元素比例是125 :55: 9 :13: 48
由此可见,虽然B的含量多,但A在比例的均衡性上更加接近推荐的比例,因此在这方面A更优
这只是在比例差异比较明显的情况下,在相差不是很明显比如我最开始提问举的例子中的数据,这时候有没有可能通过数学计算,得到一个最终的数据去比较?不知您的方法是否对我的问题可行。
还是谢谢了
[/quote]
只是把数据改成了比值而已,用比值当做坐标点其实还是一样的。[/quote]
您的意思是用比例的数据去比较么 还是说是否约到最简对它结果没有影响 ?
公式还是 √( 指标1所测的-指标1推荐的)平方+(指标2所测的-指标2推荐的)平方+...(指标m所测的-指标m推荐的)平方?代入数据还是原始数据?
如上图所示,只考虑两种指标的情况下,假设一组数据是k 1.05,na 1.12,则如同图上黑点所描述。显然红色的点比蓝色点更接近黑点,就是距离更短,也就是更具相似性。
将两维空间扩展到m维即可。[/quote]
首先谢谢您的回复,看到您的回答,按照您的计算方法是只要比较距离的差值,即
√( 指标1所测的-指标1推荐的)平方+(指标2所测的-指标2推荐的)平方+...(指标m所测的-指标m推荐的)平方
最终看哪个更小即可对么?
但目前我关注的重点不是两组数据数的大小的相似性,而是关注我所测数据整体来看各部所占比例,与对比参考数据各指标所占比例的相似性,也就是说百分比相似性的对比。应该怎么说这个词,恩,就是哪个的组成和推荐更匹配?
比如,我目前看到的推荐是
K 2000 Na 1500 Ca 800 P 700 Mg 300 各元素比例是20:15:8:7:3
目前测出2种水果中含量(mg/100g)分别为
A : K 20 Na 15 Ca 8 P 7 Mg 3 各元素比例是20:15:8:7:3
B : K 250 Na 110 Ca 18 P 26 Mg 96 各元素比例是125 :55: 9 :13: 48
由此可见,虽然B的含量多,但A在比例的均衡性上更加接近推荐的比例,因此在这方面A更优
这只是在比例差异比较明显的情况下,在相差不是很明显比如我最开始提问举的例子中的数据,这时候有没有可能通过数学计算,得到一个最终的数据去比较?不知您的方法是否对我的问题可行。
还是谢谢了
[/quote]
只是把数据改成了比值而已,用比值当做坐标点其实还是一样的。 如上图所示,只考虑两种指标的情况下,假设一组数据是k 1.05,na 1.12,则如同图上黑点所描述。显然红色的点比蓝色点更接近黑点,就是距离更短,也就是更具相似性。
将两维空间扩展到m维即可。[/quote]
首先谢谢您的回复,看到您的回答,按照您的计算方法是只要比较距离的差值,即
√( 指标1所测的-指标1推荐的)平方+(指标2所测的-指标2推荐的)平方+...(指标m所测的-指标m推荐的)平方
最终看哪个更小即可对么?
但目前我关注的重点不是两组数据数的大小的相似性,而是关注我所测数据整体来看各部所占比例,与对比参考数据各指标所占比例的相似性,也就是说百分比相似性的对比。应该怎么说这个词,恩,就是哪个的组成和推荐更匹配?
比如,我目前看到的推荐是
K 2000 Na 1500 Ca 800 P 700 Mg 300 各元素比例是20:15:8:7:3
目前测出2种水果中含量(mg/100g)分别为
A : K 20 Na 15 Ca 8 P 7 Mg 3 各元素比例是20:15:8:7:3
B : K 250 Na 110 Ca 18 P 26 Mg 96 各元素比例是125 :55: 9 :13: 48
由此可见,虽然B的含量多,但A在比例的均衡性上更加接近推荐的比例,因此在这方面A更优
这只是在比例差异比较明显的情况下,在相差不是很明显比如我最开始提问举的例子中的数据,这时候有没有可能通过数学计算,得到一个最终的数据去比较?不知您的方法是否对我的问题可行。
还是谢谢了
如上图所示,只考虑两种指标的情况下,假设一组数据是k 1.05,na 1.12,则如同图上黑点所描述。显然红色的点比蓝色点更接近黑点,就是距离更短,也就是更具相似性。
将两维空间扩展到m维即可。[/quote]
首先谢谢您的回复,看到您的回答,按照您的计算方法是只要比较距离的差值,即
√( 指标1所测的-指标1推荐的)平方+(指标2所测的-指标2推荐的)平方+...(指标m所测的-指标m推荐的)平方
最终看哪个更小即可对么?
但目前我关注的重点不是两组数据数的大小的相似性,而是关注我所测数据整体来看各部所占比例,与对比参考数据各指标所占比例的相似性,也就是说百分比相似性的对比。应该怎么说这个词,恩,就是哪个的组成和推荐更匹配?
比如,我目前看到的推荐是
K 2000 Na 1500 Ca 800 P 700 Mg 300 各元素比例是20:15:8:7:3
目前测出2种水果中含量(mg/100g)分别为
A : K 20 Na 15 Ca 8 P 7 Mg 3 各元素比例是20:15:8:7:3
B : K 250 Na 110 Ca 18 P 26 Mg 96 各元素比例是125 :55: 9 :13: 48
由此可见,虽然B的含量多,但A在比例的均衡性上更加接近推荐的比例,因此在这方面A更优
这只是在比例差异比较明显的情况下,在相差不是很明显比如我最开始提问举的例子中的数据,这时候有没有可能通过数学计算,得到一个最终的数据去比较?不知您的方法是否对我的问题可行。
还是谢谢了
