社区
Hadoop生态社区
帖子详情
beeline执行sql报错,而hive执行sql正常
满血NPC
2017-05-22 07:54:28
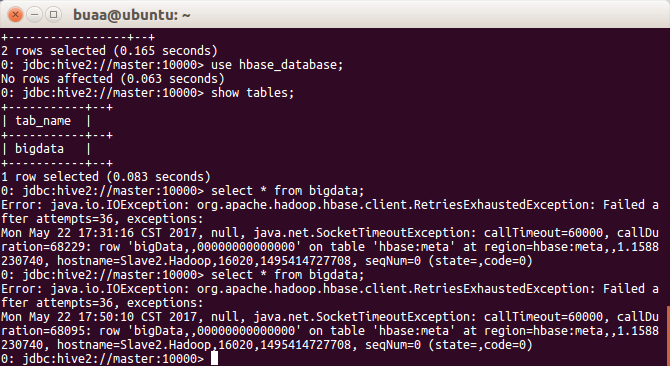
如图,hbase、hive执行命令正常;beeline执行show databases;和show tables;正常,但是执行SQL报错
Python通过impyla执行SQL也报同样的错误,还望各位前辈指点迷津。
...全文
1682
3
打赏
收藏
beeline执行sql报错,而hive执行sql正常
如图,hbase、hive执行命令正常;beeline执行show databases;和show tables;正常,但是执行SQL报错 Python通过impyla执行SQL也报同样的错误,还望各位前辈指点迷津。
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
3 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
flyliuqiong
2019-04-19
打赏
举报
回复
解决了, 版主威武
shiter
2017-06-06
打赏
举报
回复
进程身份和用户身份有啥差别啊?我是不是能接个分,哈哈
满血NPC
2017-06-06
打赏
举报
回复
1
自问自答,修改hive配置文件$HIVE_HOME/conf/hive-site.xml,添加如下配置 <property> <name>hive.server2.enable.doAs</name> <value>false</value> </property> doAs为true表示以登录hiveserver2的用户身份执行hadoop job。 为false表示以启动hiveserver2进程的用户身份去执行hadoop job。 参考自:http://blog.zhaishidan.cn/2015/05/15/jie-jue-beelinelian-jie-hiveserver2zhi-xing-sqlbao-cuo-de-wen-ti/
hive
官方文档整理
如"-e"选项允许直接在命令行中输入
SQL
查询,而"-f"选项则可以指定一个文件,
Hive
将
执行
该文件中的
SQL
命令。 3. 变量替换:
Hive
命令行提供"-d"和"--define"选项,用于在
执行
查询前定义变量。这些变量可以在查询字符...
数仓工具—
Hive
基础之
报错
后退出
执行
(24)
Hive
Cli和
Bee
line
给我们提供了
执行
SQL
文件执的功能,这时候...
hive
.cli.errors.ignore 是
Hive
的一个命令行参数,参数值是True/False,当该参数是True的时候,会继续
执行
SQL
文件即使有
SQL
报错
了,否则
执行
报错
的时
bee
line
执行
sql
文件_
hive
脚本用户 and
bee
line
Bee
line
Shell可以工作在嵌入式模式和远程模式,在嵌入式模式中,它运行一个嵌入式的
Hive
(类似于
Hive
CLI),在远程模式中,通过Thrift连接到一个单独的
Hive
Server2进程,从
Hive
0.14开始,当
Bee
l...
bee
line
执行
sql
语句_
Hive
记录-
Bee
line
常用操作命令
Bee
line
和其他工具有一些不同,
执行
查询都是正常的
SQL
输入,但是如果是一些管理的命令,比如进行连接,中断,退出,
执行
Bee
line
命令需要带上“!”,不需要终止符。常用命令介绍:1、!connect url –连接不同的
Hive
2...
hive
bee
line
连接
执行
SQL
查询
报错
hive
bee
line
连接
执行
SQL
查询
报错
bee
line
-u jdbc:
hive
2://ip:10000 -e "select * from dw.表 WHERE open_date = '20181204';"
报错
信息 ERROR : Job Submission failed with exception 'org.apache.hadoop...
Hadoop生态社区
20,845
社区成员
4,695
社区内容
发帖
与我相关
我的任务
Hadoop生态社区
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
复制链接
扫一扫
分享
社区描述
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享




