社区
脚本语言
帖子详情
关于pandas处理数据,怎么提取某一列的部分数字
yin_hei
2017-05-23 06:50:35
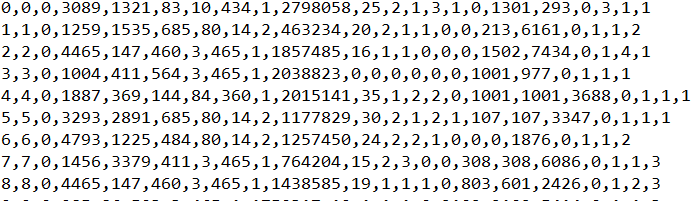
如题,用pandas读取.csv文件的数据,其中一列ID属性包含6位数字,我想将该列的属性值替换为该ID值的前两位,请问该怎么做?
另外,我的.csv数据原来没有index,第一列是label列,如下图:
但用pandas处理数据后前面多了两列index值?请问这个能删掉吗?
...全文
20386
7
打赏
收藏
关于pandas处理数据,怎么提取某一列的部分数字
如题,用pandas读取.csv文件的数据,其中一列ID属性包含6位数字,我想将该列的属性值替换为该ID值的前两位,请问该怎么做? 另外,我的.csv数据原来没有index,第一列是label列,如下图: 但用pandas处理数据后前面多了两列index值?请问这个能删掉吗?
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
7 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
马滨骞
2020-04-13
打赏
举报
回复
生成时,加index=False,就不会生成索引
yin_hei
2017-05-26
打赏
举报
回复
谢谢楼上两位,我等下试试~
大道如海
2017-05-26
打赏
举报
回复
df = pd.read_csv('../input/xx.csv', header=None) df[1] = df[1]//10000 df.to_csv('../output/xx.csv',index=False,header=False) 不一定对,参考下吧
QuantumEnergy
2017-05-26
打赏
举报
回复
with open('1.txt', 'r') as r: js = [i.strip().split(',') for i in r] for i in js: i[1] = i[1][0:2] print js
yin_hei
2017-05-25
打赏
举报
回复
引用 2 楼 uiuiy1 的回复:
你的描述与你贴的图 没看出来是对应上的, 不明白你在问什么
就是这里有两个问题: 1. 第一章图片的第二列是ID属性,我只关注前两个数字,在图片中就是数字17,我怎样才能将原来ID属性对应的6位值替换为2位的值呢? 2. 我用的pandas处理数据然后存入.csv文件,但是我发现这些.csv文件多了前面两列index值,就像第一张图是原来的数据,其中第一列是label,第二列是ID,我merge了别的.csv后,得到了第二张图,前两列是新生成的index。。第三列才是我的label,第四列是ID,以此类推。这些index该怎么删除呢?想drop或del的话并没有列名。
屎克螂
2017-05-24
打赏
举报
回复
你的描述与你贴的图 没看出来是对应上的, 不明白你在问什么
yin_hei
2017-05-23
打赏
举报
回复
有么有大神呢~
用Python中的
Pandas
处理
数据
内容介绍 1.大量练习Series
数据
结构的基础操作。 2.大量练习DataFrame
数据
结构的基础操作。...这些都是能学习
Pandas
数据
处理
的重要基础。 第4章 如果快速实现对
数据
的各分析操作,快速得到想要的报表。
pandas
对某列
数据
处理
pandas
对某列
数据
处理
终于知道
pandas
如何
提取
某行某列的值了
最近使用
pandas
来获取
数据
库的数值,但打印窗口发现,数值处一直显示有index索引,而我只想
提取
截图处id下的一个值“25833”,为此尝试了很多方法 二、尝试的方法,都失败了: 使用iloc来
提取
对应的
数据
,...
【
Pandas
数据
处理
100例】(十一):DataFrame
提取
某
一列
数据
的三种方法
大家好,我是阿光。本专栏整理了《
Pandas
数据
分析
处理
》,内包含了各种常见的
数据
处理
,以及
Pandas
内置函数的使用方法,帮助我们快速便捷的
处理
表格
数据
。正在更新中~ ✨。
pandas
数据
处理
——根据条件新增/替换某
一列
值
以前又傻又菜的时候,根据条件替换某
一列
值或新增总是会写一些for 循环去
处理
,现在发现一个更简洁的方式,就是善用
pandas
方法。 根据条件新增
一列
值 现有
数据
集如下所示: 调用apply()方法,可以作用于Series...
脚本语言
37,720
社区成员
34,239
社区内容
发帖
与我相关
我的任务
脚本语言
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
复制链接
扫一扫
分享
社区描述
JavaScript,VBScript,AngleScript,ActionScript,Shell,Perl,Ruby,Lua,Tcl,Scala,MaxScript 等脚本语言交流。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
试试用AI创作助手写篇文章吧
+ 用AI写文章




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享






