34,591
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
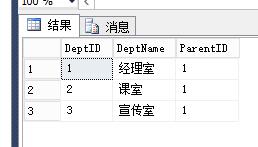
With T1(DeptID,DeptName,ParentID) as
(
select 1,N'经理室',0 union all
select 2,N'课室',1 union all
select 3,N'宣传室',2
),T2 as
(
select *,ID=deptid from T1 where ParentID=0 Union All
Select b.*,ID from T2 a Cross Apply T1 b where a.DeptID=b.ParentID
)
Select DeptID,DeptName,ID as ParentID from T2

--测试数据
if not object_id(N'Tempdb..#T') is null
drop table #T
Go
Create table #T([DeptID] int,[DeptName] nvarchar(23),[ParentID] int)
Insert #T
select 1,N'经理室',0 union all
select 2,N'课室',1 union all
select 3,N'宣传室',2
Go
--测试数据结束
;WITH cte AS (
SELECT DeptID ,
DeptName ,
CASE WHEN ParentID = 0 THEN DeptID
ELSE ParentID
END AS ParentID
FROM #T
WHERE ParentID = 0
UNION ALL
SELECT a.DeptID,a.DeptName,b.DeptID FROM #T a JOIN cte b ON a.ParentID = b.DeptID
)
SELECT DeptID,DeptName,(SELECT MIN(ParentID) FROM cte) AS ParentID FROM cte