大对象直接进入老年代有几个比较坑爹的地方:
JDK版本 1.7.0_79
新对象大于Eden区总大小的时候,会被直接扔到老年代,实验:
-Xms20M -Xmx20M -Xmn10M -XX:+PrintGCDetails -XX:+UseParNewGC
7M<8M Eden,分配到Eden:
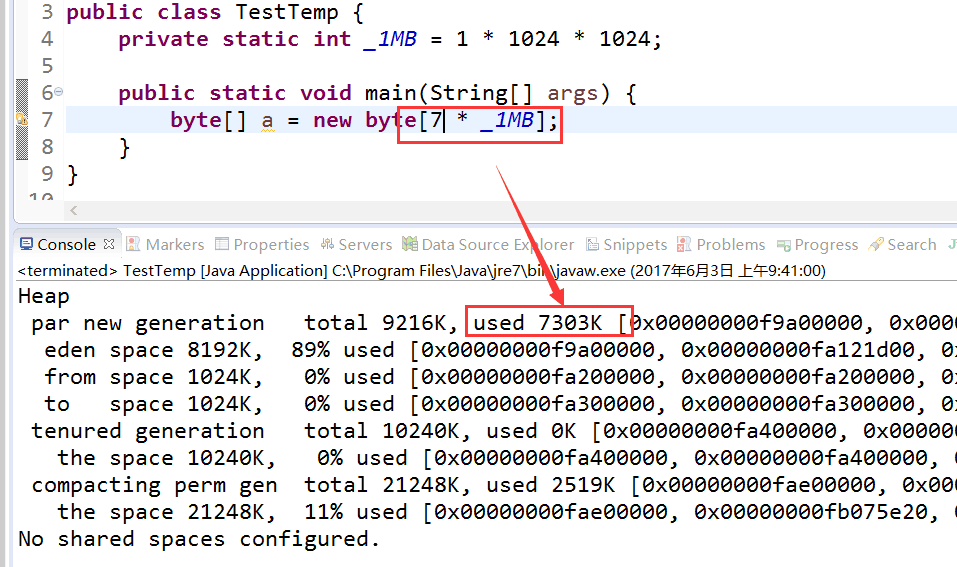
8M = 8M Eden,但是小于整个年轻代大小9M,直接分配到Old Gen:

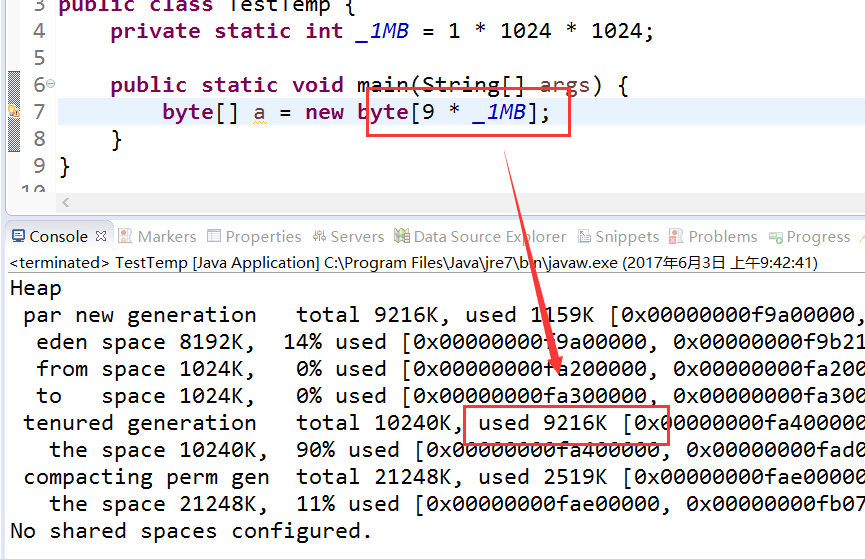
9M> 8M,直接分配到Old Gen:
6M < 8M,但是大于Eden剩余空间,触发了MinorGC,6M被分到了Eden:
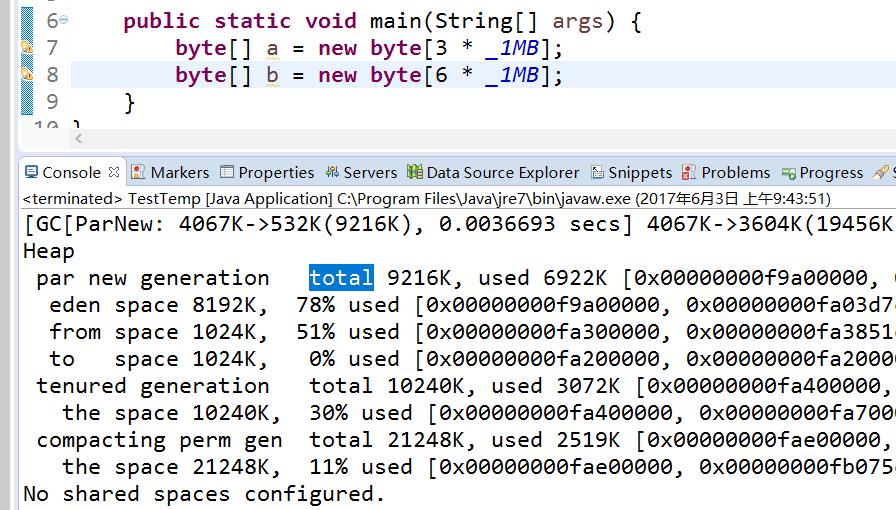
以上说明不是大于Eden剩余空间就分配到Old Gen,而是大于Eden总空间
说回PretenureSizeThreshold这个参数,
-Xms200m -Xmx200m -Xmn100m -XX:+PrintGCDetails -XX:SurvivorRatio=3 -XX:+PrintFlagsFinal -XX:PretenureSizeThreshold=31m -XX:+UseParNewGC
到t3触发MinorGC后,Eden区还剩yue45m,大于t4的43m,t4被分配到Eden
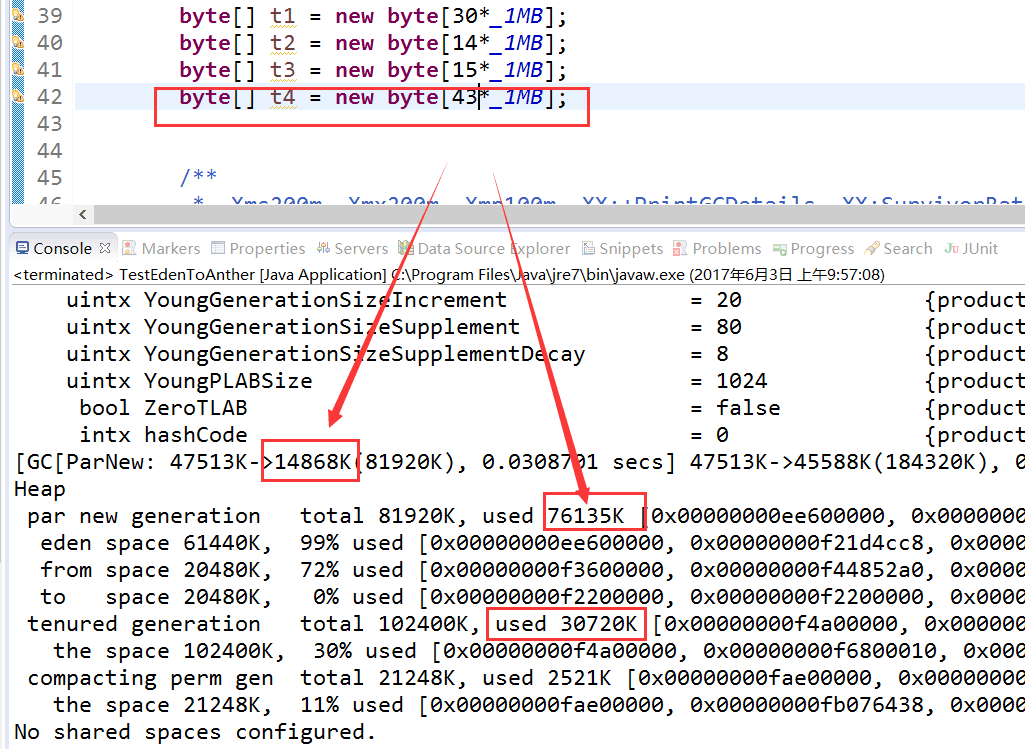
这里t3触发MinorGC后,Eden剩余空间大约45m,t4 45m,直接分配到了Old Gen,
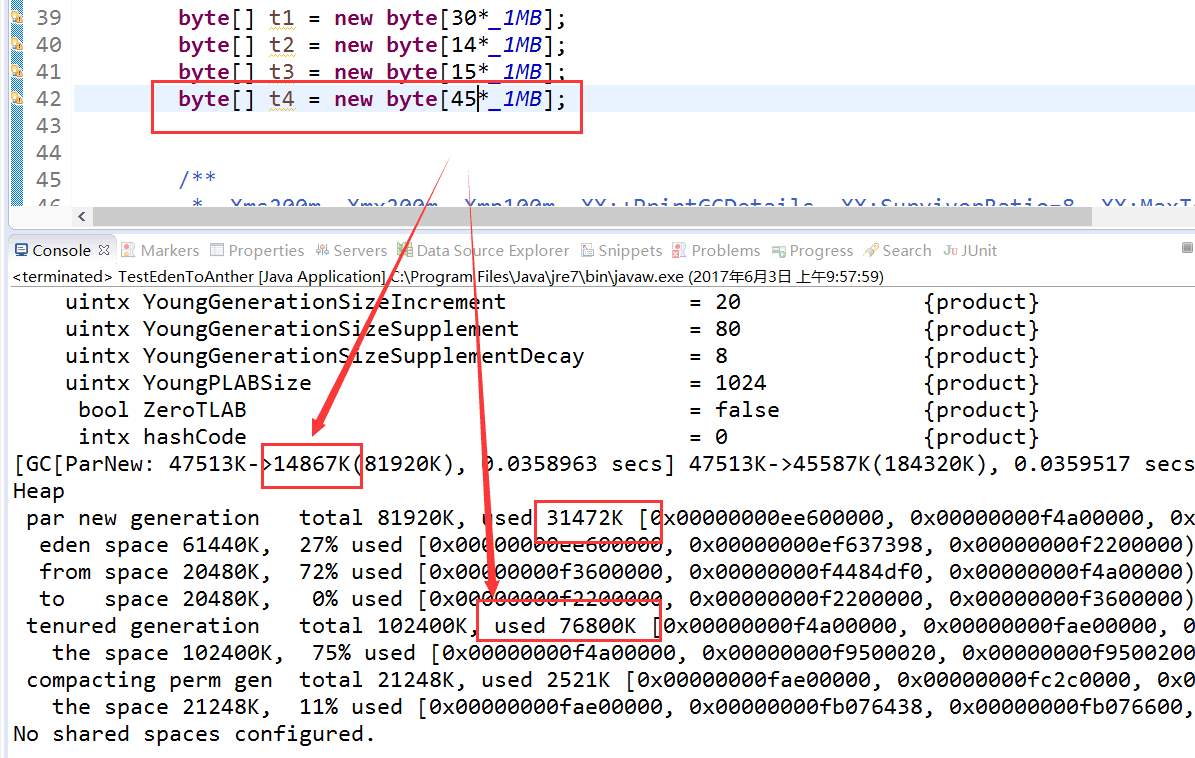
以上,PretenureSizeThreshold好像只在第二种场景才起了作用?不是大于PretenureSizeThreshold设置的值就直接扔老年代吗?望大神们解答!!


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享







