


37,744
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
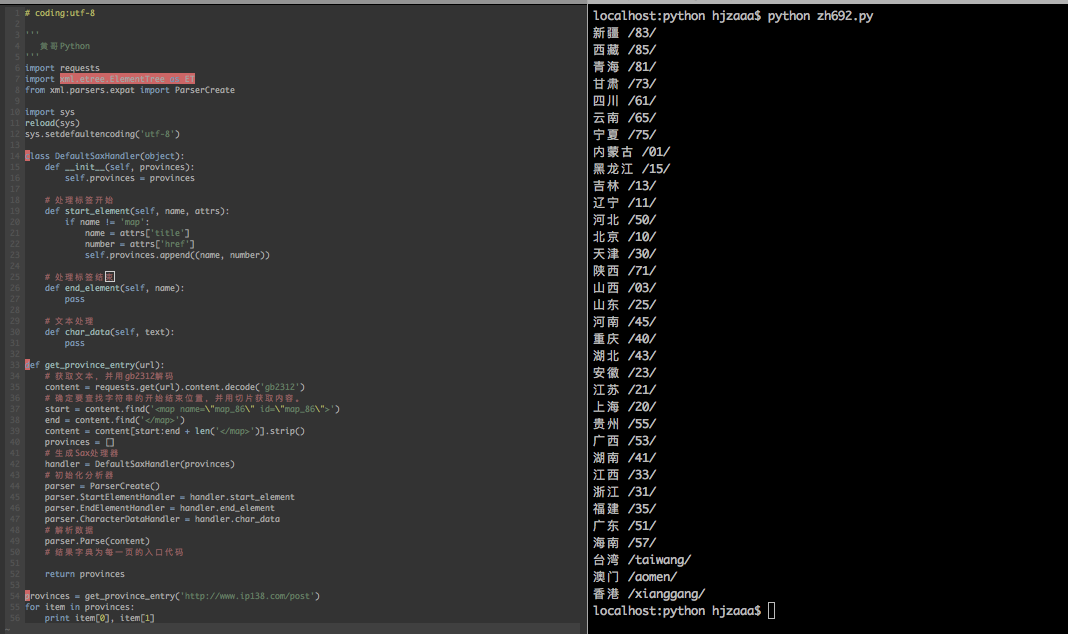
# coding=utf-8
import requests
import xml.etree.ElementTree as ET
from xml.parsers.expat import ParserCreate
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
class DefaultSaxHandler(object):
def __init__(self, provinces):
self.provinces = provinces
# 处理标签开始
def start_element(self, name, attrs):
if name != 'map':
name = attrs['title']
number = attrs['href']
self.provinces.append((name, number))
# 处理标签结束
def end_element(self, name):
pass
# 文本处理
def char_data(self, text):
pass
def get_province_entry(url):
# 获取文本,并用gb2312解码
content = requests.get(url).content.decode('gb2312')
# 确定要查找字符串的开始结束位置,并用切片获取内容。
start = content.find('<map name=\"map_86\" id=\"map_86\">')
end = content.find('</map>')
content = content[start:end + len('</map>')].strip()
provinces = []
# 生成Sax处理器
handler = DefaultSaxHandler(provinces)
# 初始化分析器
parser = ParserCreate()
parser.StartElementHandler = handler.start_element
parser.EndElementHandler = handler.end_element
parser.CharacterDataHandler = handler.char_data
# 解析数据
parser.Parse(content)
# 结果字典为每一页的入口代码
return provinces
provinces = get_province_entry('http://www.ip138.com/post')
print provinces




import sys
reload(sys)
sys.setdefaultencoding('utf-8')

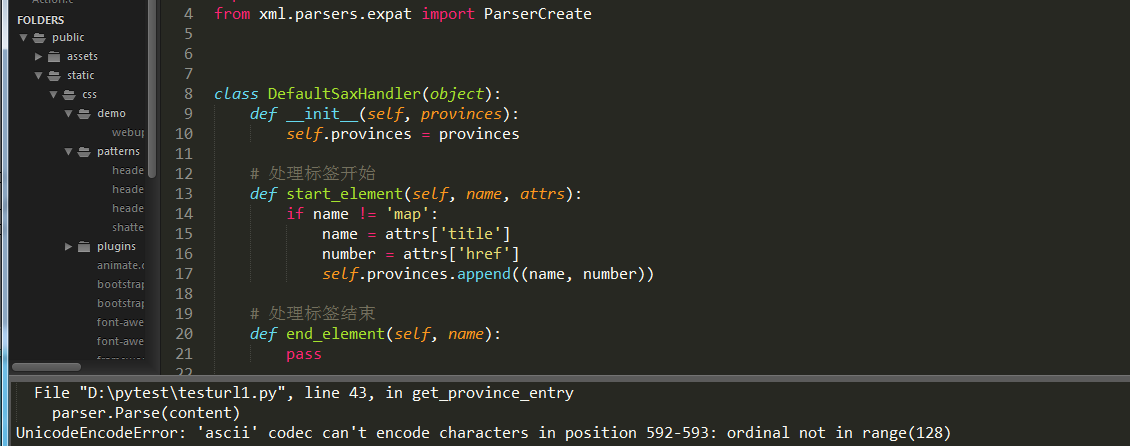 ascii问题
ascii问题

