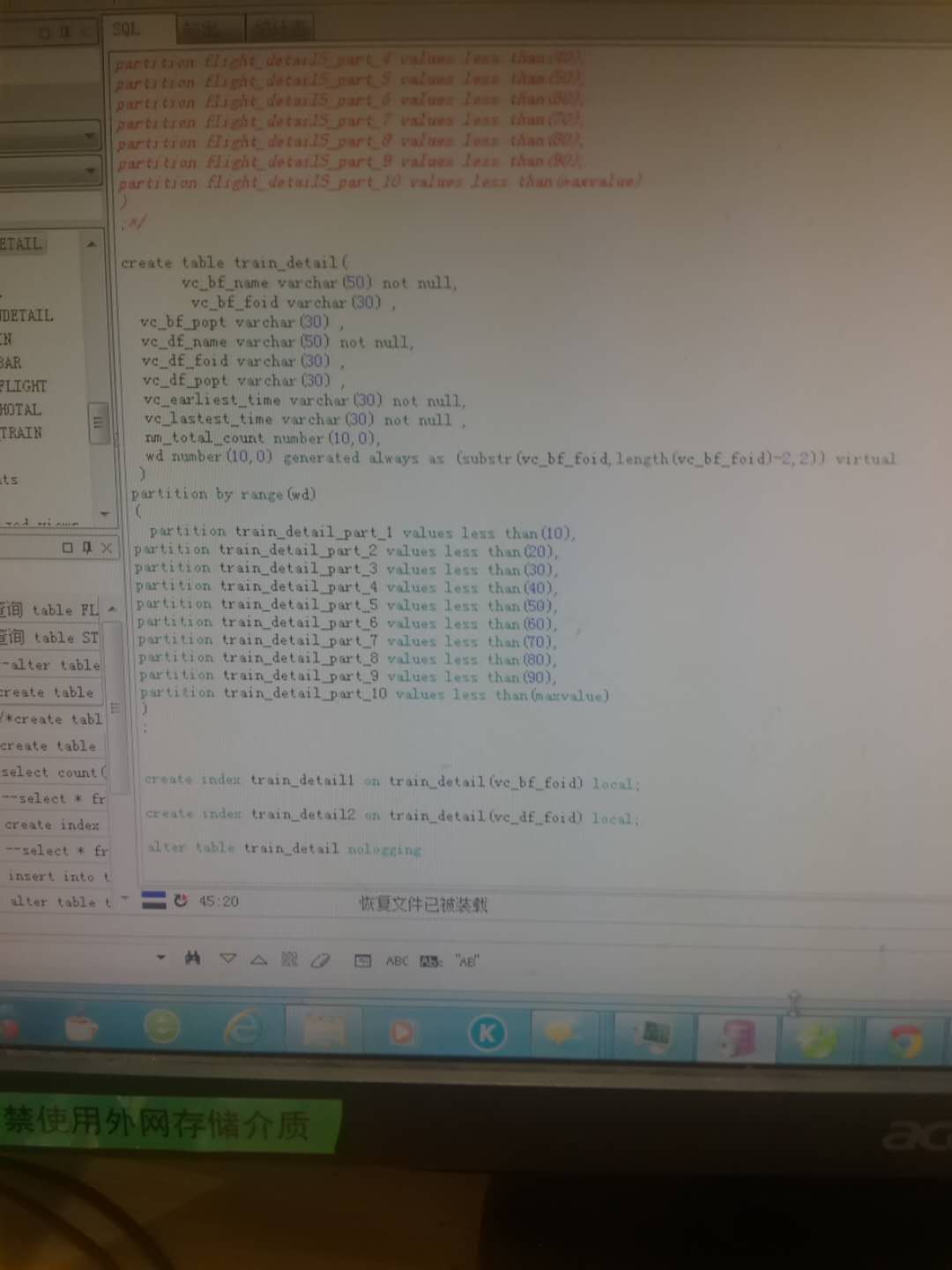
大神们好,我现在遇到个问题 ,想往oracle插几亿的数据 需要索引 现在分了区插 还是挺慢的 ,我还有什么方式提高速度的?目前所有的分区都在一个表空间。最开始的速度有每秒2w 到1千万之后每秒只有两三千了
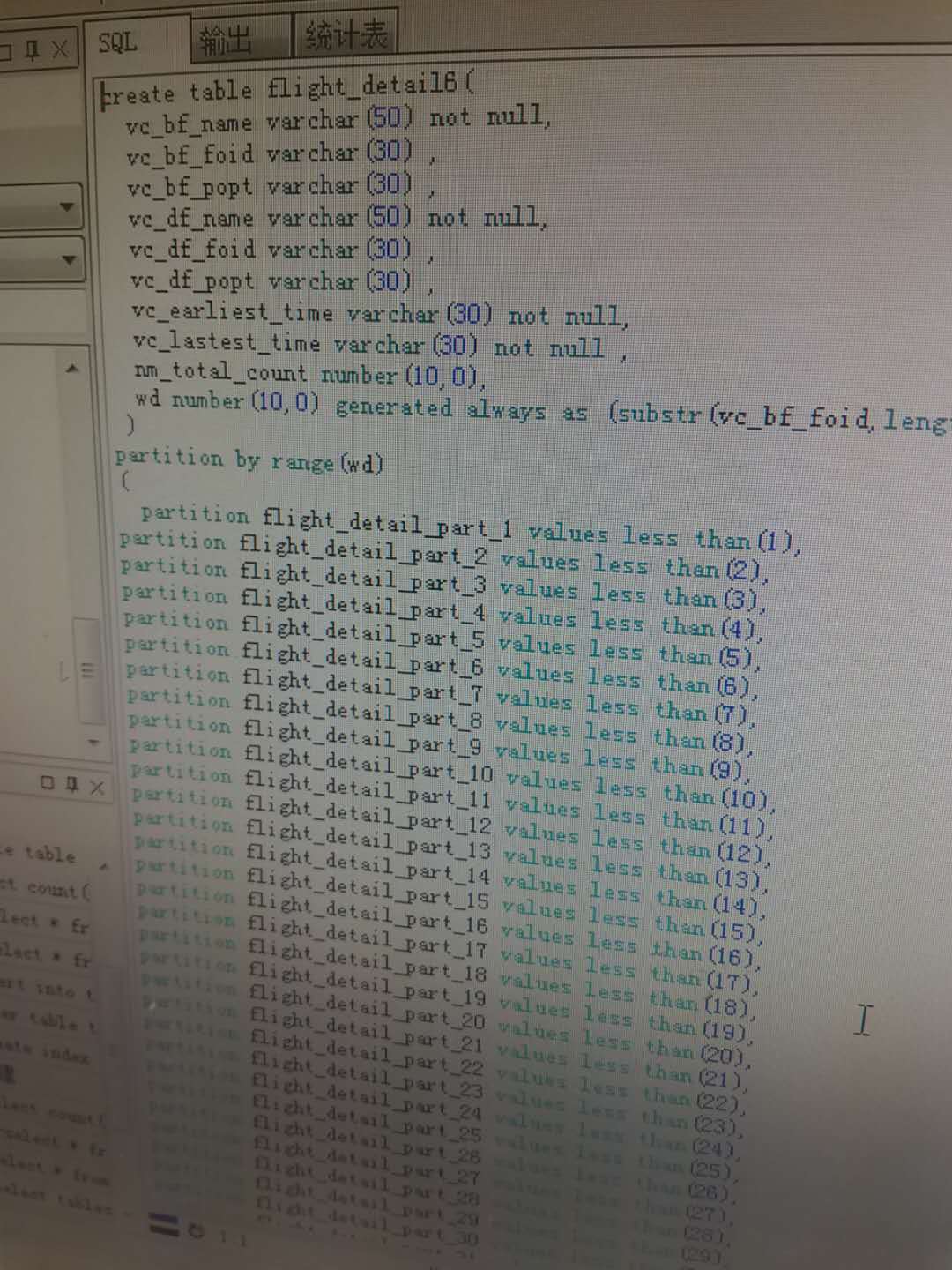
这个是我的 创表语句,目前都在一个表空间里
我用的merge into的方法插入(和insert into 效率差不多)
mergeinto语句如下
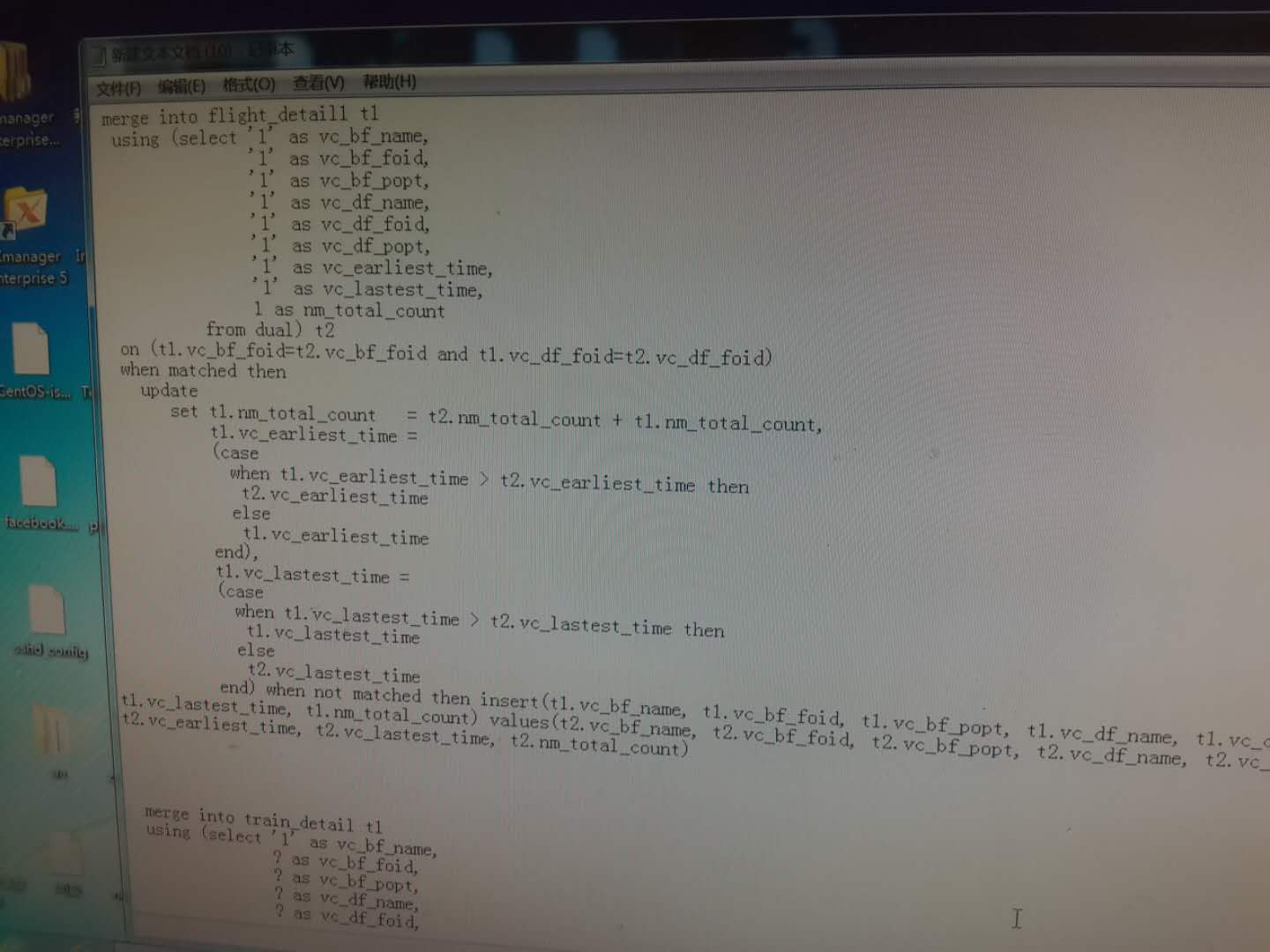
vc_bf_foid与vc_df_foid都做了索引 索引字段是必须要的,因为除了插入操作还需要以这两个字段做更新操作。
大神们棒棒忙啊,这个问题困扰我好久了,各种测试都是慢


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享