先来看看Hbase整个结构的图形:
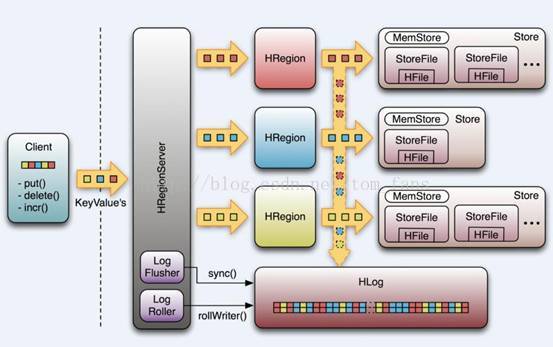
实际上说,hbase结构真的不复杂,相比传统的RDBMS来说,应该要简单。 HBASE整个物理层存储其实最后就是HFile,读内存block cache, 写缓存memstore, write buffer,客户端也能缓存rowkey位置信息。
客户端写数据先写入 memstore,默认为128M, 整个默认memstore大小为HEAP*0.4,现在假设你的 region heap设置为4G,那么你总共的memstore=1.6G, 我们先把问题简单化,假设每个table只有一个列簇(实际当然是可以多个),那就是说每个region对应一个memstore, 1个表包含多个region,根据rowkey startkey, endkey 来划分。 表述这些我是想说,我们的内存也许是有限的,按照1.6G内存来算,一个memstore为128M,那请问能支撑几个region ? 所以很显然,如果我一个表有200个region,每个region同时插入数据,请问1.6G如何来满足我每个region有一个memstore ?
根据我个人测试,在这种情况下,memstore=HEAP*0.4/region数量, 那么上面1.6G/200=8M, 请看下面日志,我测试10000个线程,并发插入,每次刷新memstore是40M,
从下面日志记录也能看到Region memstore size=40.3 M, 为什么?不应该是128M吗?
2017-07-04 15:28:23,130 INFO org.apache.Hadoop.hbase.regionserver.HRegion: Finished memstore flush of ~40.50 MB/42467600, currentsize=202.34 KB/207200 for region usertable,user2709,1499075907888.cf743601bfe13f3f7275e01626633d89. in 471ms, sequenceid=518724, compaction requested=false
2017-07-04 15:28:26,693 INFO org.apache.hadoop.hbase.regionserver.MemStoreFlusher: Flush of region usertable,user5409,1499075907888.bdabdbfd453e477181c025bab17780fe. due to global heap pressure. Total Memstore size=612.5 M, Region memstore size=40.3 M
2017-07-04 15:28:26,694 INFO org.apache.hadoop.hbase.regionserver.HRegion: Flushing 1/1 column families, memstore=40.31 MB
好了,暂时不聊memstore了,继续, 说说block cache,其实从缓存命中率来看,命中率真的很低,基本维持在20-30%, 那么问题来了,到底要不要block cache ? 或者说哪些表需要 block cache ? 在分数数据过程,有时候会载入非常大的表,可能只做偶尔差查询, block cache的默认值也等于HEAP*0.4。 一个大表载入就有可能清空整个block cache之前的内容, 因此每次监控到的block cache 命中率都非常低,我们有必要思考一下,什么表开启block cache对我们的应用有帮助? 什么表必须关闭 block cache ,哪些表必须in memory .
至于write buffer , 从1M到20M,坦白的说我没有看到太大区别,通常在5M左右性能都还可以,增加内存,好像作用不大,减少内存还是有影响的,所以我自己的HBASE write buffer一般设置6M。
上面描述的属于内存方面的问题,恕我愚钝,除了上述几个内存能调整,我真的再也找不到额外的内存参数了。
物理存储方面,其实就是HFile了,很多人喜欢写 HStore, 或者 storefile, 鬼都不知道写什么,1个 region 包含多个hfile, 每个表又包含多个region , 在物理文件层,又有合并和拆分操作,默认3个文件合并,拆分操作有3个规则,看你选哪一个, 简单的就是超过默认10G,就拆分, 复杂的有一些运算方式,不管怎么运算,始终逃离不了max file size这个规则,我有时候在想,如果表很小,有必要那么多规则吗? 如果表大,根据大小拆分即可, 1种规则就够了,非要弄3个规则,实在不行,我手动再拆分不行吗? 要那么多规则干什么?
合并也好,拆分也好,都不过是为了获得更好的性能, HBASE相对来说多region线性扩展性能还是可以的,集群越大,性能越好。 文件太多,零散,对HBASE本身也是一个压力,从客户端访问,到获取记录,经过3层访问,从zk, meta, 再到表定位rowkey, 为了解决这个3层访问,HBASE因此有了客户端缓存的功能,减少3层访问过程。 好了,回到拆分和合并吧, 默认3个文件就合并,合并之后文件大小达到最大 hfile size又进行拆分, 来来去去,反反复复,你看HBASE日志能够发现,一个繁忙的系统经常在干合并拆分的工作。 因此我们有必要思考一下memstore, 128M够吗? 这个还是要看你实际刷新频率吧, 反正我是用默认值。 另外如果一个极大的系统不停刷新,有一个参数控制,当达到10个文件,HBASE会有90秒的写入阻止, 实际就是给时间让系统去合并文件,如果90秒还没完成,再放开写入。 如果真的出现这种情况,10个文件哪里够? 至少给多少自己看着办。
另外就是HLOG了,为了保证恢复,数据刷新之前必须要保证进入HLOG,这个和传统数据库的方式没有区别。 为了解决单个HLOG的性能问题,HBASE后期版本引入多个HLOG,也就是hbase.wal.provider ,hbase.wal.storage.policy 参数,应该是说每个表都有HLOG吧, 因为如果写入量大,那么HLOG负载其实是很大的,通常来说,不管是传统Oracle还是MySQL,都建议用最好的磁盘保证性能,HBASE也不例外。
说到这里上面那图形里面的东西好像基本已经说完了, 那么继续乱弹其他的吧。 上面提到的都是一个基本概念, 能完全优化上面那些东西还不够,在实际HADOOP系统中,有人用Spark 访问HBASE, 有人用map reduce ,有人就是用Java API而已。 Spark , map reduce必须要关注map , reduce数量,像我做的几次测试,吞吐量一直上不去,是因为我的测试环境只有5个nodemanager, 机器是8个vcores, 以为着每次我最多能跑39个map reduce任务,如果有几百个任务要处理,其他任务全部处于pending,很显然,这非常影响性能,spark 道理也一样。 不管怎么说不管你使用什么方式,最后都逃离不过几个参数设置, auto flush , write buffer, write ahead log , 实际的测试, auto flush 影响最大,其次是 write buffer, 很多人说write ahead log也会影响,从理论上没错,100%会有很大影响,但是奇怪的是我测试没有测出区别,但是我仍然相信,一定会有影响。 另外插入HBASE也就是put , List<put> , 建议使用 List<put>, 要知道,每一次插入都是一次RPC操作,就算没有性能区别,我们也要尽量减少RPC交互,List<put> 把很多操作集合成一个操作,就一个RPC。
Java系统都逃不掉说垃圾回收问题,根据现在系统,region server, memstore, 这2个内存要尤其注意,必须实时监控,一旦发现内存不够,尽量能扩展region server,分散region , 我用10000个线程测试,memstore实际来说还是很稳定,没有出现大问题, 只是不停的在刷新,并没有出现什么警告,反而是Hlog写入报警,说非常繁忙,对于内存我没有太多的建议,很多人可能会调整垃圾回收策略,我用CDH默认的CMS, 我只有一个建议,就是memstore不要太大,如果频繁刷新的话,内存又大,应该是很消耗时间的,所以我设置为512M,中规中矩吧。
经常会听到一些问题,诸如你的HBASE优化的怎么样? HBASE有什么可优化的? 弄来弄去就上面些东西, 我们要做的是实时监控,了解整个HBASE,了解你的应用,每秒有多少插入? 多少并发? memstore多久刷新一次? Hlog写入性能如何? 内存是否垃圾回收频繁? 内存最大值和已经达到的最大值相差多少? 至少我们要先在硬件层面上保证能够支撑系统。 至于rowkey怎么设置,这些问题很简单,能满足业务,又能负载均衡的写入HBASE就好的ROWKEY, 实在不行我做二级索引。我这里数据量其实不太大,大概每小时单表4亿插入,字节100左右,没有出现什么问题。
HBASE还有很多内部工具,比如我们使用COUNT很慢,通过HBASE的自带类来统计会快很多。还有一些表迁移snapshot是我认为最快的方式,从一个HBASE迁移到另外一个HBASE, 那其他一些导入导出用copytable, export 都行, 自己用mapreduce写也一样,我之前自己用mapreduce写统计表数量的和HBASE自带的类性能差不多,所以很多东西还是靠mapreduce比较方便, spark也行,看个人怎么选。
就弹这些吧。




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



 写得不错
写得不错


