

37,741
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

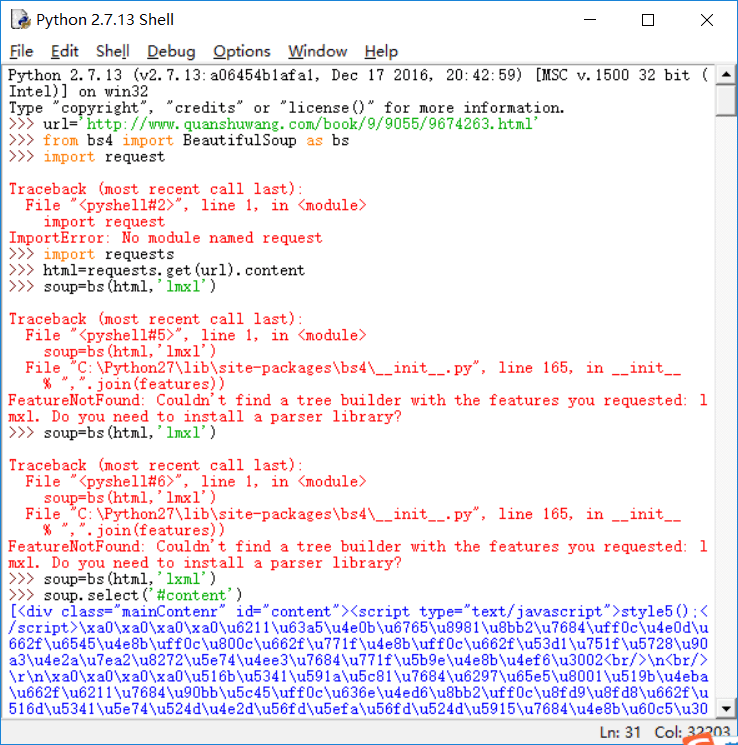

#coding=utf-8
import urllib
import re
html = urllib.urlopen('http://www.quanshuwang.com/book/9/9055/9674263.html').read()
text = html.decode('gbk')
reg = r'<script type="text/javascript">style5\(\);</script>([\s\S]*?)<script type="text/javascript">style6'
pattern = re.compile(reg)
match = pattern.findall(text)
if match:
for txt in match:
print txt

reg = r'style5\(\);</script>(.*?)<script type="text/javascript">style6' #提取内容,发现出错,提取不到
print re.findall(reg,text,re.DOTALL)
