

37,738
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
# -*- coding: utf-8 -*-
"""
Created on Fri Aug 11 16:31:42 2017
@author: lart
"""
import urllib.request
import re, time
def req_open_html(url):
print('req_open_html begin')
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0'}
request = urllib.request.Request(url, headers=headers)
html = urllib.request.urlopen(request).read().decode('GBK')
print('req_open_html end')
return html
def re_find_match(re_string, operation, html):
print('re_find_match begin')
pattern = re.compile(re_string, re.I)
if operation == 'findall':
result = pattern.findall(html)
elif operation == 'match':
result = pattern.match(html)
else:
print('this operation is invalid')
exit(-1)
print('re_find_match end')
return result
if __name__ == '__main__':
url_base = 'http://www.7kankan.la/book/1/'
html = req_open_html(url_base)
findall_title = re_find_match(r'<title>(.+?)</title>', 'findall', html)
findall_article = re_find_match(r'<dd class="col-md-3"><a href=[\',"](.+?)[\',"] title=[\',"](.+?)[\',"]>', 'findall', html)
with open(findall_title[0] + '.txt', 'w+', encoding='utf-8') as open_file:
print('article文件打开', findall_article)
for i in range(len(findall_article)):
print(i)
open_file.write(findall_article[i][1] + '\n ---------------------------------------------- \n')
url_arctile = url_base + findall_article[i][0]
html_article = req_open_html(url_arctile)
findall_article_txet = re_find_match(r' (.+?)<br />', 'findall', html_article)
findall_article_next = findall_article[i][0].replace('.html', '_2.html')
url_arctile_next = url_base + findall_article_next
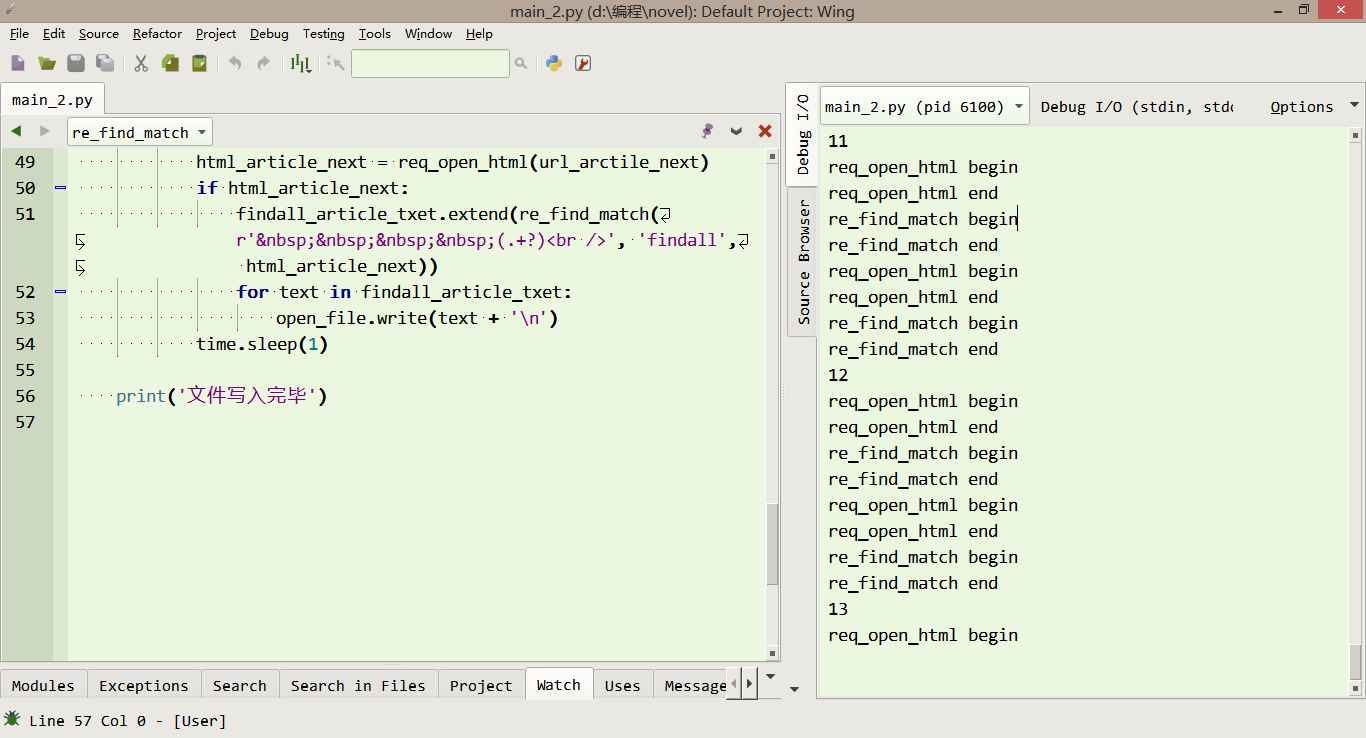
html_article_next = req_open_html(url_arctile_next)
if html_article_next:
findall_article_txet.extend(re_find_match(r' (.+?)<br />', 'findall', html_article_next))
for text in findall_article_txet:
open_file.write(text + '\n')
time.sleep(1)
print('文件写入完毕')

# -*- coding: utf-8 -*-
"""
Created on Fri Aug 11 16:31:42 2017
@author: lart
"""
import urllib.request
import re, time
import socket
def req_open_html(url):
print('req_open_html begin')
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0'}
request = urllib.request.Request(url, headers=headers)
NET_STATUS = False
while not NET_STATUS:
try:
html = urllib.request.urlopen(request, data=None, timeout=3).read().decode('GBK')
print('NET_STATUS is good')
print('req_open_html end')
return html
except socket.timeout:
print('NET_STATUS is not good')
NET_STATUS = False
def re_find_match(re_string, operation, html):
print('re_find_match begin')
pattern = re.compile(re_string, re.I)
if operation == 'findall':
result = pattern.findall(html)
elif operation == 'match':
result = pattern.match(html)
else:
print('this operation is invalid')
exit(-1)
print('re_find_match end')
return result
if __name__ == '__main__':
url_base = 'http://www.7kankan.la/book/1/'
html = req_open_html(url_base)
findall_title = re_find_match(r'<title>(.+?)</title>', 'findall', html)
findall_article = re_find_match(r'<dd class="col-md-3"><a href=[\',"](.+?)[\',"] title=[\',"](.+?)[\',"]>', 'findall', html)
with open(findall_title[0] + '.txt', 'w+', encoding='utf-8') as open_file:
print('article文件打开', findall_article)
for i in range(len(findall_article)):
print(i)
open_file.write(findall_article[i][1] + '\n ---------------------------------------------- \n')
url_arctile = url_base + findall_article[i][0]
html_article = req_open_html(url_arctile)
findall_article_txet = re_find_match(r' (.+?)<br />', 'findall', html_article)
findall_article_next = findall_article[i][0].replace('.html', '_2.html')
url_arctile_next = url_base + findall_article_next
html_article_next = req_open_html(url_arctile_next)
if html_article_next:
findall_article_txet.extend(re_find_match(r' (.+?)<br />', 'findall', html_article_next))
for text in findall_article_txet:
open_file.write(text + '\n')
time.sleep(1)
print('文件写入完毕')



