37,720
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
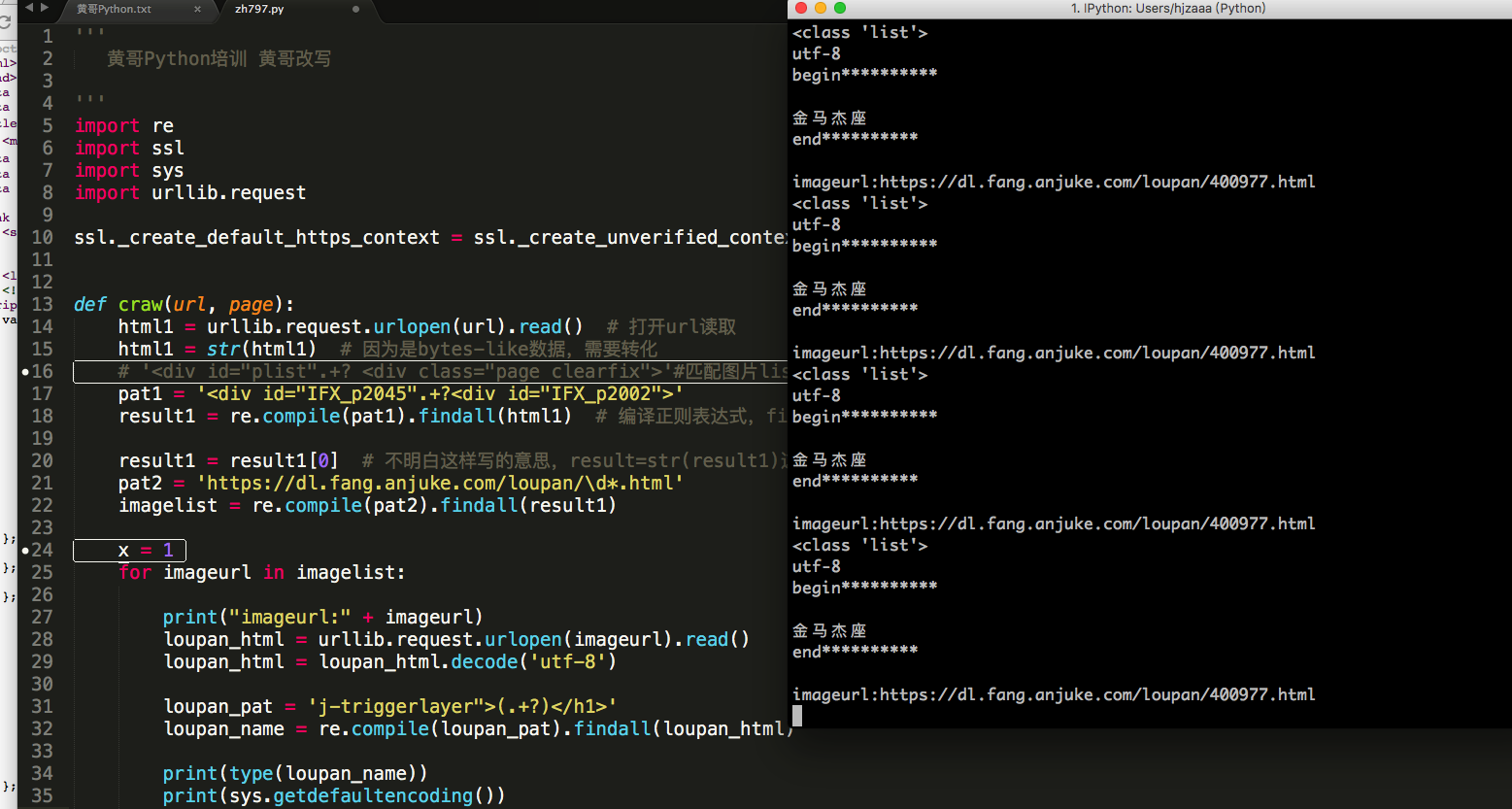
#!/usr/bin/env python3
# -*- coding: utf-8
import re
import urllib.request
import sys
def craw(url,page):
html1=urllib.request.urlopen(url).read()#打开url读取
html1=str(html1)#因为是bytes-like数据,需要转化
pat1='<div id="IFX_p2045".+?<div id="IFX_p2002">'#'<div id="plist".+? <div class="page clearfix">'#匹配图片list的开头和结尾,找网页中出现一次的字符串作为标识
result1=re.compile(pat1).findall(html1)#编译正则表达式,findall 找到所有符合正则的列表
result1=result1[0]#不明白这样写的意思,result=str(result1)这样写也能实现
pat2='https://dl.fang.anjuke.com/loupan/\d*.html'
imagelist=re.compile(pat2).findall(result1)
#print(imagelist)
x=1
for imageurl in imagelist:
#imagename="C:/"+str(x)+".html"#保存到本地的路径,如果要放到文件夹,一定要提前新建好
#print(imagename)
print("imageurl:"+imageurl)
loupan_html=urllib.request.urlopen(imageurl).read()
loupan_html=str(loupan_html)
loupan_pat='j-triggerlayer">(.+?)</h1>'#<h1 id="j-triggerlayer">金马杰座</h1>
loupan_name=re.compile(loupan_pat).findall(loupan_html)
loupan_name=str(loupan_name)
print(type(loupan_name))
print(sys.getdefaultencoding())
print(loupan_name.encode().decode('utf-8'))
for i in range(1,2):
url="https://dl.fang.anjuke.com/loupan/all/p"+str(i)+"/"#翻页
craw(url,i)
print(i)