社区
Hadoop生态社区
帖子详情
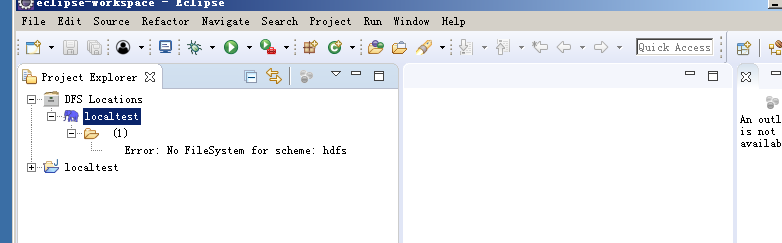
请HADOOP大神帮助下,开发环境问题ERROR:No FileSystem for scheme:hdfs
播种真理的码农
2017-09-03 10:38:00
Windows/liunux环境下的开发环境都有这个问题
hadoop本地可以启动
但是在eclispe上配置DFS locations 就报错
Error: No FileSystem for scheme: hdfs
请大神帮助
...全文
648
2
打赏
收藏
请HADOOP大神帮助下,开发环境问题ERROR:No FileSystem for scheme:hdfs
Windows/liunux环境下的开发环境都有这个问题 hadoop本地可以启动 但是在eclispe上配置DFS locations 就报错 Error: No FileSystem for scheme: hdfs 请大神帮助
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
2 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
一剑侵心
2017-09-21
打赏
举报
回复
那个插件不稳定。
碧水幽幽泉
2017-09-18
打赏
举报
回复
高效率秘籍1 能量管理
假如今天透支身体数小时,下周你可能要为此偿还更多的时间。
良好的能量管理有两步:
(1)增加你的能量储备。
(2)将你的日程表由线性的改为循环式的。
能量储备:
(1)每周有3~5次运动吗?如果你的回答为否,你正在削弱你的潜在能量水平,除非你的医生不让你参加运动,否则最少每天要抽出40分钟来锻炼身体,每天运动一点点,学习效果更明显。
(2)每晚有七八个小时的睡眠吗?有些人睡四五个小时就够了,学习工作劲头十足,不过我想你我又不是这种神人,那么还是老老实实睡到自然醒吧。熬夜对学习来说有百害而无一利。睡得好,脑袋才清醒。
(3)你吃的是什么?你的食谱是高糖、高脂肪、高蛋白质的吗?请放弃它吧,我建议你吃粗纤维和粗加工的食物,这样的食物可以让你一天的血糖水平保持平稳,
(4)一天之内,你喝几杯水?最快让你丧失能量的办法就是脱水。随意最好身边常备水杯,想起来就饮些。
(5)一天你吃几餐?如果你的回答是中餐、晚餐以及时不时吃点早餐,那么你的能量有可能不足。理想的饮食应该是少吃多餐,一天吃四五餐,每次吃七分饱,这样可以保证你一天内的营养供应持续稳定,睡前吃一点能让你第二天早上精力充沛。
循环式日程:
线性的计划是平均安排时间执行工作,而循环式作息计划则先集中小部分时间做大部分工作。这种计划安排能让你做到有张有弛,而不是死气沉沉,像个机器人。
(1)一周休息一天。我总是抽出一周中的一天,什么事也不做,将7天的活放在6天里完成
(2)晚上不干活儿。将一天的工作放在早上集中完成,早早完成工作,晚上你就有几小时的空闲了。
(3)设定90分钟。给定自己90分钟,集中精力完成某个学习任务,一旦90分钟结束,停止工作
关于能量管理,最好的一本书是《精力管理:管理精力,而非时间,是高效、健康与快乐的基础》(The Power of Full Engagement)
高效率秘籍2 不要“学习”(Don't study)
我从不“学习”。我会阅读课本,复习笔记,也会做作业和各种练习,但是我从来没有进行所谓的“学习”。如果没有明确自己究竟想达到什么目的,就去不停地“学习”,实在是对宝贵时间资源的浪费。
注: 要有目的的学习,而不是漫无目的的什么都学。
“这是一个模糊、容易产生歧义的概念,学习这个词给大多数学生增加了太多的精神压力。他们认为如果不能一直待在图书馆、坐在书桌前沉思苦读,就会有负罪感。于是学生生活变成了一种持久的自我斗争过程——总是试图多‘学习’,但总是感到收获少。这就好像总是做出一副吃饭的样子,但是吃下去得不多,消化得不够,吸收得也不好,如此这般学习效果怎么可能好呢?”
不用“学习”这个笼统的容易产生歧义的词,我们只定义学习过程中需要做的那些活动。
(1)阅读材料。
(2)完成各项作业和在课堂上做笔记。
(3)应用整体性学习方法处理某些难点。
(4)考试前,针对学习材料做一次笔记流。
除非把学习需要做的具体活动列出来,否则你可能花费大量的时间在所谓的“学习”表象上,而不是真正地学会了什么。
高效率秘籍3 绝不拖延
最佳答案(在多数情况下)应该是,一次性完成作业比分次完成更节省时间。此外,如果你采用周/日目标方法来完成作业,效果会更好。
周/日目标体系是我知道的最好的对抗延迟的方法,办法很简单:
每周周末,列一个清单,包括所有的任务、作业以及你想在下周完成的读书和学习活动。
除非在一周内出现意想不到的事情,否则你就有责任完成这个清单,不过也不必超过清单所规定的任务。
如果这一周特别忙碌,你可能会推迟完成任务。如果这一周很清闲,你可能会提前完成任务。
注: 把目标任务完成就行了。提前完成的话,剩余时间就自由玩耍。
每天晚上,检查周计划,列出每日目标清单。
高效率秘籍4 批处理
批处理最适用于将那些需要时间不长的零散工作放在一起做。你不能将整个课程都安排在考试前一天批量看完。超过3个小时的工作用批处理,效果就不好了。
当然,如果一项作业花费的时间不会超过8小时,我就坐在凳子上一鼓作气完成它。
注意力阈值就是指集中完成某项工作的最长时间。通过不断接受越来越多的批处理,你可以逐渐提高你的注意力阈值。
推荐《批处理:节省时间、减轻压力的20个小技巧》。
高效率秘籍5 有组织
(1)所有的物品都放在固定的位置。作业、课外作业以及约会日期都记录在固定的地方。没有固定地方的结果就是混乱
(2)随身携带一个记事本。每天随时记录,
(3)坚持日历和做事清单。
组织技能可以大大提高学习效率,而且能缓解压力。
文/翱翔GTD(简书作者)
原文链接:http://www.jianshu.com/p/39ba5e40eef3
hadoop
工具包及eclipse插件
包含
hadoop
工具包及eclipse插件
hadoop
bin.zip为工具包,解压官方haddop包之后把
hadoop
bin解压的丢到haddop目录下
hadoop
-eclipse-plugin-2.7.2为
hadoop
的eclipse插件,丢到eclipse的plugin目录
hadoop
2.8.0 下测试,可以显示Map/Reduce project,但是在DFS Locations下总提示
Error
:No
File
System For
Scheme
:
hdfs
Hadoop
权威指南 第二版(中文版)
内容简介 本书从
Hadoop
的缘起开始,由浅入深,结合理论和实践,全方位地介绍
Hadoop
这一高性能处理海量数据集的理想工具。全书共16章,3个附录,涉及的主题包括:Haddoop简介;MapReduce简介;
Hadoop
分布式文件系统;
Hadoop
的I/O、MapReduce应用程序开发;MapReduce的工作机制;MapReduce的类型和格式;MapReduce的特性;如何构建
Hadoop
集群,如何管理
Hadoop
;Pig简介;Hbase简介;Hive简介;ZooKeeper简介;开源工具Sqoop,最后还提供了丰富的案例分析。 本书是
Hadoop
权威参考,程序员可从中探索如何分析海量数据集,管理员可以从中了解如何安装与运行
Hadoop
集群。 目录 第1章 初识
Hadoop
数据!数据! 数据存储与分析 与其他系统相比 关系型数据库管理系统 网格计算 志愿计算 1.3.4
Hadoop
发展简史 Apache
Hadoop
和
Hadoop
生态圈 第2章 关于MapReduce 一个气象数据集 数据的格式 使用Unix工具进行数据分析 使用
Hadoop
分析数据 map阶段和reduce阶段 横向扩展 合并函数 运行一个分布式的MapReduce作业
Hadoop
的Streaming Ruby版本 Python版本
Hadoop
Pipes 编译运行 第3章
Hadoop
分布式文件系统
HDFS
的设计
HDFS
的概念 数据块 namenode和datanode 命令行接口 基本文件系统操作
Hadoop
文件系统 接口 Java接口 从
Hadoop
URL中读取数据 通过
File
System API读取数据 写入数据 目录 查询文件系统 删除数据 数据流 文件读取剖析 文件写入剖析 一致模型 通过 distcp并行拷贝 保持
HDFS
集群的均衡
Hadoop
的归档文件 使用
Hadoop
归档文件 不足 第4章
Hadoop
I/O 数据完整性
HDFS
的数据完整性 Local
File
System Checksum
File
System 压缩 codec 压缩和输入切分 在MapReduce中使用压缩 序列化 Writable接口 Writable类 实现定制的Writable类型 序列化框架 Avro 依据文件的数据结构 写入Sequence
File
Map
File
第5章 MapReduce应用开发 配置API 合并多个源文件 可变的扩展 配置
开发环境
配置管理 辅助类GenericOptionsParser,Tool和ToolRunner 编写单元测试 mapper reducer 本地运行测试数据 在本地作业运行器上运行作业 测试驱动程序 在集群上运行 打包 启动作业 MapReduce的Web界面 获取结果 作业调试 使用远程调试器 作业调优 分析任务 MapReduce的工作流 将
问题
分解成MapReduce作业 运行独立的作业 第6章 MapReduce的工作机制 剖析MapReduce作业运行机制 作业的提交 作业的初始化 任务的分配 任务的执行 进度和状态的更新 作业的完成 失败 任务失败 tasktracker失败 jobtracker失败 作业的调度 Fair Scheduler Capacity Scheduler shuffle和排序 map端 reduce端 配置的调优 任务的执行 推测式执行 重用JVM 跳过坏记录 任务执行环境 第7章 MapReduce的类型与格式 MapReduce的类型 默认的MapReduce作业 输入格式 输入分片与记录 文本输入 二进制输入 多种输入 数据库输入(和输出) 输出格式 文本输出 二进制输出 多个输出 延迟输出 数据库输出 第8章 MapReduce的特性 计数器 内置计数器 用户定义的Java计数器 用户定义的Streaming计数器 排序 准备 部分排序 总排序 二次排序 联接 map端联接 reduce端联接 边数据分布 利用JobConf来配置作业 分布式缓存 MapReduce库类 第9章 构建
Hadoop
集群 集群规范 网络拓扑 集群的构建和安装 安装Java 创建
Hadoop
用户 安装
Hadoop
测试安装 SSH配置
Hadoop
配置 配置管理 环境设置
Hadoop
守护进程的关键属性
Hadoop
守护进程的地址和端口
Hadoop
的其他属性 创建用户帐号 安全性 Kerberos和
Hadoop
委托令牌 其他安全性改进 利用基准测试程序测试
Hadoop
集群
Hadoop
基准测试程序 用户的作业 云上的
Hadoop
Amazon EC2上的
Hadoop
第10章 管理
Hadoop
HDFS
永久性数据结构 安全模式 日志审计 工具 监控 日志 度量 Java管理扩展(JMX) 维护 日常管理过程 委任节点和解除节点 升级 第11章 Pig简介 安装与运行Pig 执行类型 运行Pig程序 Grunt Pig Latin编辑器 示例 生成示例 与数据库比较 PigLatin 结构 语句 表达式 1.4.4 类型 模式 函数 用户自定义函数 过滤UDF 计算UDF 加载UDF 数据处理操作 加载和存储数据 过滤数据 分组与连接数据 对数据进行排序 组合和分割数据 Pig实战 并行处理 参数代换 第12章 Hive 1.1 安装Hive 1.1.1 Hive外壳环境 1.2 示例 1.3 运行Hive 1.3.1 配置Hive 1.3.2 Hive服务 1.3.3 Metastore 1.4 和传统数据库进行比较 1.4.1 读时模式(Schema on Read)vs.写时模式(Schema onWrite) 1.4.2 更新、事务和索引 1.5 HiveQL 1.5.1 数据类型 1.5.2 操作和函数 1.6 表 1.6.1 托管表(Managed Tables)和外部表(External Tables) 1.6.2 分区(Partitions)和桶(Buckets) 1.6.3 存储格式 1.6.4 导入数据 1.6.5 表的修改 1.6.6 表的丢弃 1.7 查询数据 1.7.1 排序(Sorting)和聚集(Aggregating) 1.7.2 MapReduce脚本 1.7.3 连接 1.7.4 子查询 1.7.5 视图(view) 1.8 用户定义函数(User-Defined Functions) 1.8.1 编写UDF 1.8.2 编写UDAF 第13章 HBase 2.1 HBasics 2.1.1 背景 2.2 概念 2.2.1 数据模型的“旋风之旅” 2.2.2 实现 2.3 安装 2.3.1 测试驱动 2.4 客户机 2.4.1 Java 2.4.2 Avro,REST,以及Thrift 2.5 示例 2.5.1 模式 2.5.2 加载数据 2.5.3 Web查询 2.6 HBase和RDBMS的比较 2.6.1 成功的服务 2.6.2 HBase 2.6.3 实例:HBase在Streamy.com的使用 2.7 Praxis 2.7.1 版本 2.7.2
HDFS
2.7.3 用户接口(UI) 2.7.4 度量(metrics) 2.7.5 模式设计 2.7.6 计数器 2.7.7 批量加载(bulkloading) 第14章 ZooKeeper 安装和运行ZooKeeper 示例 ZooKeeper中的组成员关系 创建组 加入组 列出组成员 ZooKeeper服务 数据模型 操作 实现 一致性 会话 状态 使用ZooKeeper来构建应用 配置服务 具有可恢复性的ZooKeeper应用 锁服务 生产环境中的ZooKeeper 可恢复性和性能 配置 第15章 开源工具Sqoop 获取Sqoop 一个导入的例子 生成代码 其他序列化系统 深入了解数据库导入 导入控制 导入和一致性 直接模式导入 使用导入的数据 导入的数据与Hive 导入大对象 执行导出 深入了解导出 导出与事务 导出和Sequence
File
第16章 实例分析
Hadoop
在Last.fm的应用 Last.fm:社会音乐史上的革命
Hadoop
a Last.fm 用
Hadoop
产生图表 Track Statistics程序 总结
Hadoop
和Hive在Facebook的应用 概要介绍
Hadoop
a Facebook 假想的使用情况案例 Hive
问题
与未来工作计划 Nutch 搜索引擎 背景介绍 数据结构 Nutch系统利用
Hadoop
进行数据处理的精选实例 总结 Rackspace的日志处理 简史 选择
Hadoop
收集和存储 日志的MapReduce模型 关于Cascading 字段、元组和管道 操作 Tap类,
Scheme
对象和Flow对象 Cascading实战 灵活性
Hadoop
和Cascading在ShareThis的应用 总结 在Apache
Hadoop
上的TB字节数量级排序 使用Pig和Wukong来探索10亿数量级边的 网络图 测量社区 每个人都在和我说话:Twitter回复关系图 degree(度) 对称链接 社区提取 附录A 安装Apache
Hadoop
先决条件 安装 配置 本机模式 伪分布模式 全分布模式 附录B Cloudera’s Distribution for
Hadoop
附录C 准备NCDC天气数据
Hadoop
实战教程
Hadoop
是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop
实现了一个分布式文件系统( Distributed
File
System),其中一个组件是
HDFS
(
Hadoop
Distributed
File
System)。
Hadoop
的框架最核心的设计就是:
HDFS
和MapReduce。
HDFS
为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算 。
Hadoop
权威指南(中文版)2015上传.rar
第1章 初识
Hadoop
数据!数据! 数据存储与分析 与其他系统相比 关系型数据库管理系统 网格计算 志愿计算 1.3.4
Hadoop
发展简史 Apache
Hadoop
和
Hadoop
生态圈 第2章 关于MapReduce 一个气象数据集 数据的格式 使用Unix工具进行数据分析 使用
Hadoop
分析数据 map阶段和reduce阶段 横向扩展 合并函数 运行一个分布式的MapReduce作业
Hadoop
的Streaming Ruby版本 Python版本
Hadoop
Pipes 编译运行 第3章
Hadoop
分布式文件系统
HDFS
的设计
HDFS
的概念 数据块 namenode和datanode 命令行接口 基本文件系统操作
Hadoop
文件系统 接口 Java接口 从
Hadoop
URL中读取数据 通过
File
System API读取数据 写入数据 目录 查询文件系统 删除数据 数据流 文件读取剖析 文件写入剖析 一致模型 通过 distcp并行拷贝 保持
HDFS
集群的均衡
Hadoop
的归档文件 使用
Hadoop
归档文件 不足 第4章
Hadoop
I/O 数据完整性
HDFS
的数据完整性 Local
File
System Checksum
File
System 压缩 codec 压缩和输入切分 在MapReduce中使用压缩 序列化 Writable接口 Writable类 实现定制的Writable类型 序列化框架 Avro 依据文件的数据结构 写入Sequence
File
Map
File
第5章 MapReduce应用开发 配置API 合并多个源文件 可变的扩展 配置
开发环境
配置管理 辅助类GenericOptionsParser,Tool和ToolRunner 编写单元测试 mapper reducer 本地运行测试数据 在本地作业运行器上运行作业 测试驱动程序 在集群上运行 打包 启动作业 MapReduce的Web界面 获取结果 作业调试 使用远程调试器 作业调优 分析任务 MapReduce的工作流 将
问题
分解成MapReduce作业 运行独立的作业 第6章 MapReduce的工作机制 剖析MapReduce作业运行机制 作业的提交 作业的初始化 任务的分配 任务的执行 进度和状态的更新 作业的完成 失败 任务失败 tasktracker失败 jobtracker失败 作业的调度 Fair Scheduler Capacity Scheduler shuffle和排序 map端 reduce端 配置的调优 任务的执行 推测式执行 重用JVM 跳过坏记录 任务执行环境 第7章 MapReduce的类型与格式 MapReduce的类型 默认的MapReduce作业 输入格式 输入分片与记录 文本输入 二进制输入 多种输入 数据库输入(和输出) 输出格式 文本输出 二进制输出 多个输出 延迟输出 数据库输出 第8章 MapReduce的特性 计数器 内置计数器 用户定义的Java计数器 用户定义的Streaming计数器 排序 准备 部分排序 总排序 二次排序 联接 map端联接 reduce端联接 边数据分布 利用JobConf来配置作业 分布式缓存 MapReduce库类 第9章 构建
Hadoop
集群 集群规范 网络拓扑 集群的构建和安装 安装Java 创建
Hadoop
用户 安装
Hadoop
测试安装 SSH配置
Hadoop
配置 配置管理 环境设置
Hadoop
守护进程的关键属性
Hadoop
守护进程的地址和端口
Hadoop
的其他属性 创建用户帐号 安全性 Kerberos和
Hadoop
委托令牌 其他安全性改进 利用基准测试程序测试
Hadoop
集群
Hadoop
基准测试程序 用户的作业 云上的
Hadoop
Amazon EC2上的
Hadoop
第10章 管理
Hadoop
HDFS
永久性数据结构 安全模式 日志审计 工具 监控 日志 度量 Java管理扩展(JMX) 维护 日常管理过程 委任节点和解除节点 升级 第11章 Pig简介 安装与运行Pig 执行类型 运行Pig程序 Grunt Pig Latin编辑器 示例 生成示例 与数据库比较 PigLatin 结构 语句 表达式 1.4.4 类型 模式 函数 用户自定义函数 过滤UDF 计算UDF 加载UDF 数据处理操作 加载和存储数据 过滤数据 分组与连接数据 对数据进行排序 组合和分割数据 Pig实战 并行处理 参数代换 第12章 Hive 1.1 安装Hive 1.1.1 Hive外壳环境 1.2 示例 1.3 运行Hive 1.3.1 配置Hive 1.3.2 Hive服务 1.3.3 Metastore 1.4 和传统数据
eclipse连接
hadoop
报错
Error
:No
File
System for
scheme
:
hdfs
问题
:eclipse连接
hadoop
报错
Error
:No
File
System for
scheme
:
hdfs
环境:
hadoop
2.8.3,jdk1.8.0-121,eclipse oxygen,
hadoop
-eclipse-plugin-2.8.3
问题
分析:如果配置有
问题
可参考另一篇文章: ubuntu安装配置eclipse+
hadoop
开发环境
(十分详细)如果配置文件没有出错,就是插件有
问题
,...
Hadoop生态社区
20,808
社区成员
4,690
社区内容
发帖
与我相关
我的任务
Hadoop生态社区
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
复制链接
扫一扫
分享
社区描述
Hadoop生态大数据交流社区,致力于有Hadoop,hive,Spark,Hbase,Flink,ClickHouse,Kafka,数据仓库,大数据集群运维技术分享和交流等。致力于收集优质的博客
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章





 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


