27,581
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
--测试数据
if not object_id(N'Tempdb..#T') is null
drop table #T
Go
Create table #T([ID] int,[公司名] nvarchar(24),[Name] nvarchar(25),[电话] varchar(20),[职务] nvarchar(24),[Name1] nvarchar(29),[电话1] nvarchar(29),[职务1] nvarchar(32),[网址] nvarchar(32))
Insert #T
select 1,N'测试公司',N'Andy',255252134,N'经理',N'Billy',null,N'总经理',N'www.text.com' union all
select 2,N'测试公司',N'Billy',255252136,null,N'Andy',N'255252135',N'经理',null union all
select 3,N'测试公司',N'Andy',255252135,null,null,null,null,null
--select 4,N'测试公司',N'Andy',255252135,N'经理',N'Billy',N'255252136',N'总经理',N'www.text.com'
Go
--测试数据结束
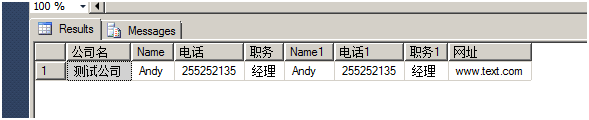
Select [公司名],
STUFF((select ','+Name from #t t where [公司名]=t.[公司名] and Name is not null for xml path('')), 1, 1, '') as Name,
STUFF((select ','+[电话] from #t t where [公司名]=t.[公司名] and [电话] is not null for xml path('')), 1, 1, '') as [电话],
STUFF((select ','+[职务] from #t t where [公司名]=t.[公司名] and [职务] is not null for xml path('')), 1, 1, '') as [职务],
STUFF((select ','+[Name1] from #t t where [公司名]=t.[公司名] and Name1 is not null for xml path('')), 1, 1, '') as [Name1],
STUFF((select ','+[电话1] from #t t where [公司名]=t.[公司名] and [电话1] is not null for xml path('')), 1, 1, '') as [电话1],
STUFF((select ','+[职务1] from #t t where [公司名]=t.[公司名] and [职务1] is not null for xml path('')), 1, 1, '') as [职务1],
STUFF((select ','+[网址] from #t t where [公司名]=t.[公司名] and [网址] is not null for xml path('')), 1, 1, '') as [网址]
From #t
Group By [公司名]



--测试数据
if not object_id(N'Tempdb..#T') is null
drop table #T
Go
Create table #T([ID] int,[公司名] nvarchar(24),[Name] nvarchar(25),[电话] int,[职务] nvarchar(24),[Name1] nvarchar(29),[电话1] nvarchar(29),[职务1] nvarchar(32),[网址] nvarchar(32))
Insert #T
select 1,N'测试公司',N'Andy',255252134,N'经理',N'Billy',N'总经理',N'www.text.com',null union all
select 2,N'测试公司',N'Billy',255252136,N'Andy',N'255252135',N'经理',null,null union all
select 3,N'测试公司',N'Andy',255252135,null,null,null,null,null union all
select 4,N'测试公司',N'Andy',255252135,N'经理',N'Billy',N'255252136',N'总经理',N'www.text.com'
Go
--测试数据结束
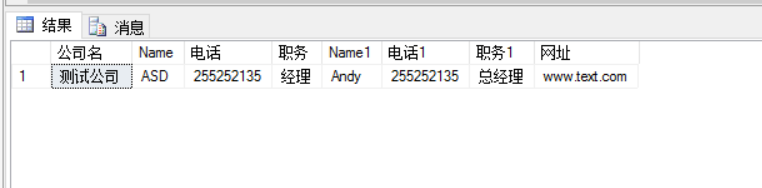
;WITH cte AS (
Select *,ROW_NUMBER()OVER(PARTITION BY 公司名 ORDER BY ID DESC) AS num from #T
)
SELECT * FROM cte WHERE 公司名 LIKE '%测试%' AND num=1


--测试数据
if not object_id(N'Tempdb..#T') is null
drop table #T
Go
Create table #T([ID] int,[公司名] nvarchar(24),[Name] nvarchar(25),[电话] varchar(20),[职务] nvarchar(24),[Name1] nvarchar(29),[电话1] nvarchar(29),[职务1] nvarchar(32),[网址] nvarchar(32))
Insert #T
select 1,N'测试公司',N'Andy',255252134,N'经理',N'Billy',null,N'总经理',N'www.text.com' union all
select 2,N'测试公司',N'Billy',255252136,null,N'Andy',N'255252135',N'经理',null union all
select 3,N'测试公司',N'Andy',255252135,null,null,null,null,null
--select 4,N'测试公司',N'Andy',255252135,N'经理',N'Billy',N'255252136',N'总经理',N'www.text.com'
Go
--测试数据结束
Select [公司名],
case when charindex(',',name)>0 then Reverse(Substring(REVERSE(Name),1,Charindex(',',REVERSE(Name))-1)) else name end as Name,
case when charindex(',',[电话])>0 then Reverse(Substring(REVERSE([电话]),1,Charindex(',',REVERSE([电话]))-1)) else [电话] end as [电话],
case when charindex(',',[职务])>0 then Reverse(Substring(REVERSE([职务]),1,Charindex(',',REVERSE([职务]))-1)) else [职务] end as [职务],
case when charindex(',',name1)>0 then Reverse(Substring(REVERSE(Name1),1,Charindex(',',REVERSE(Name1))-1)) else name1 end as Name1,
case when charindex(',',[电话1])>0 then Reverse(Substring(REVERSE([电话1]),1,Charindex(',',REVERSE([电话1]))-1)) else [电话1] end as [电话1],
case when charindex(',',[职务1])>0 then Reverse(Substring(REVERSE([职务1]),1,Charindex(',',REVERSE([职务1]))-1)) else [职务1] end as [职务1],
case when charindex(',',[网址])>0 then Reverse(Substring(REVERSE([网址]),1,Charindex(',',REVERSE([网址]))-1)) else [网址] end as [网址]
From (
Select [公司名],
STUFF((select ','+Name from #t t where [公司名]=t.[公司名] and Name is not null for xml path('')), 1, 1, '') as Name,
STUFF((select ','+[电话] from #t t where [公司名]=t.[公司名] and [电话] is not null for xml path('')), 1, 1, '') as [电话],
STUFF((select ','+[职务] from #t t where [公司名]=t.[公司名] and [职务] is not null for xml path('')), 1, 1, '') as [职务],
STUFF((select ','+[Name1] from #t t where [公司名]=t.[公司名] and Name1 is not null for xml path('')), 1, 1, '') as [Name1],
STUFF((select ','+[电话1] from #t t where [公司名]=t.[公司名] and [电话1] is not null for xml path('')), 1, 1, '') as [电话1],
STUFF((select ','+[职务1] from #t t where [公司名]=t.[公司名] and [职务1] is not null for xml path('')), 1, 1, '') as [职务1],
STUFF((select ','+[网址] from #t t where [公司名]=t.[公司名] and [网址] is not null for xml path('')), 1, 1, '') as [网址]
From #t
Group By [公司名]
) a