22,296
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
-- 使用row_number直接获取数据,效率很低,需要1秒以上才能返回数据
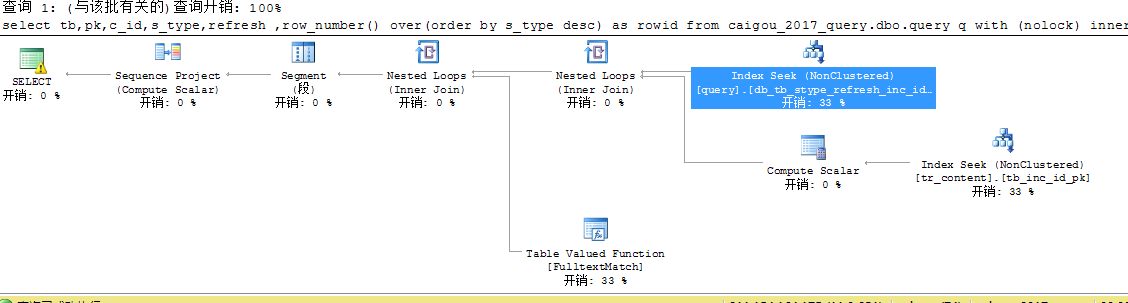
select tb,pk,c_id,s_type,refresh
,row_number() over(order by s_type desc) as rowid
from caigou_2017_query.dbo.query q with (nolock)
inner join (select dbid,tbid,pkid from caigou_2017_triggers.dbo.tr_content with (nolock) where contains(content,'"分析测试"')) b on q.pk=b.pkid and q.tb=b.tbid
where db=15 and tb=1682105033
--不使用row_number测试,效率很高
select tb,pk,c_id,s_type,refresh
--,row_number() over(order by s_type desc) as rowid
from caigou_2017_query.dbo.query q with (nolock)
inner join (select dbid,tbid,pkid from caigou_2017_triggers.dbo.tr_content with (nolock) where contains(content,'"分析测试"')) b on q.pk=b.pkid and q.tb=b.tbid
where db=15 and tb=1682105033
-- 对子集进行row_number,效率和使用row_number一样
select *
--,row_number() over(order by s_type desc) as rowid
from (
select tb,pk,c_id,s_type,refresh
from caigou_2017_query.dbo.query q with (nolock)
inner join (select dbid,tbid,pkid from caigou_2017_triggers.dbo.tr_content with (nolock) where contains(content,'"分析测试"')) b on q.pk=b.pkid and q.tb=b.tbid
where db=15 and tb=1682105033
) a
-- 使用临时表,然后row_number,效率和没有使用row_number的指令一样
select tb,pk,c_id,s_type,refresh
into #tb
--,row_number() over(order by s_type desc) as rowid
from caigou_2017_query.dbo.query q with (nolock)
inner join (select dbid,tbid,pkid from caigou_2017_triggers.dbo.tr_content with (nolock) where contains(content,'"分析测试"')) b on q.pk=b.pkid and q.tb=b.tbid
where db=15 and tb=1682105033
select *
,row_number() over(order by s_type desc) as rowid
from #tb
drop table #tb



select tb,pk,c_id,s_type,refresh
,row_number() over(order by s_type desc) as rowid
from caigou_2017_query.dbo.query q with (NOLOCK,PAGLOCK)
inner join (select dbid,tbid,pkid from caigou_2017_triggers.dbo.tr_content with (nolock) where contains(content,'"分析测试"')) b on q.pk=b.pkid and q.tb=b.tbid
where db=15 and tb=1682105033
select tb,pk,c_id,s_type,refresh
,row_number() over(order by s_type desc) as rowid
from caigou_2017_query.dbo.query q with (NOLOCK,PAGLOCK)
inner join (select dbid,tbid,pkid from caigou_2017_triggers.dbo.tr_content with (nolock) where contains(content,'"分析测试"')) b on q.pk=b.pkid and q.tb=b.tbid
where db=15 and tb=1682105033
CREATE NONCLUSTERED INDEX [db_tb_tp_refresh_inc_id_pk_sp_cid_stype_new] ON [dbo].[query]
(
[db] ASC,
[tb] ASC,
[s_type] DESC,
[refresh] ASC
)
INCLUDE ( [id],
[pk],
[sphere],
[c_id]
) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [db_tb_tp_refresh_inc_id_pk_sp_cid_stype_new] ON [dbo].[query]
(
[db] ASC,
[s_type] DESC,
[tb] ASC,
[tp] ASC,
[refresh] ASC
)
INCLUDE ( [id],
[pk],
[sphere],
[c_id],
) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [db_tb_tp_refresh_inc_id_pk_sp_cid_stype_new] ON [dbo].[query]
(
[db] ASC,
[s_type] DESC,
[tb] ASC,
[tp] ASC,
[refresh] ASC
)
INCLUDE ( [id],
[pk],
[sphere],
[c_id],
) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [db_tb_inc_pk_cid_stype_refresh] ON [dbo].[query]
(
[db] ASC,
[tb] ASC
)
INCLUDE (
pk,c_id,s_type,refresh
) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GOCREATE NONCLUSTERED INDEX [db_tb_tp_refresh_inc_id_pk_sp_cid_stype] ON [dbo].[query]
(
[db] ASC,
[tb] ASC,
[tp] ASC,
[refresh] ASC
)
INCLUDE ( [id],
[pk],
[sphere],
[c_id],
[s_type]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO