社区
C#
帖子详情
Tesseract不能打开eng是怎么回事?
r00_a2lBUR
2017-09-14 10:57:49
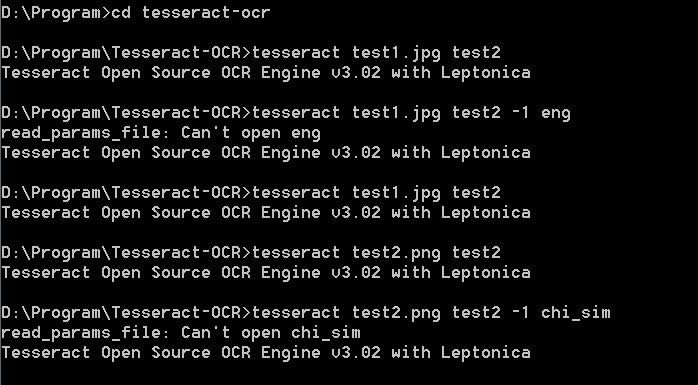
我想在C#中调用Tesseract,参考文章:http://www.cnblogs.com/cnlian/p/5765871.html 下载了一个安装包,按上面的提示,运行:tesseract test1.jpg test2 -1 eng报错,运行:tesseract test1.jpg就可以运行,运行tesseract test2.png test2 -1 chi_sim也报错:
这是不是要下载什么语言包?
...全文
392
2
打赏
收藏
Tesseract不能打开eng是怎么回事?
我想在C#中调用Tesseract,参考文章:http://www.cnblogs.com/cnlian/p/5765871.html 下载了一个安装包,按上面的提示,运行:tesseract test1.jpg test2 -1 eng报错,运行:tesseract test1.jpg就可以运行,运行tesseract test2.png test2 -1 chi_sim也报错: 这是不是要下载什么语言包?
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
2 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
r00_a2lBUR
2017-10-13
打赏
举报
回复
引用 1 楼 qq2495534085 的回复:
把1换成小写的L就可以。
试了一下,确实可以。
_乾坤_
2017-10-13
打赏
举报
回复
把1换成小写的L就可以。
Tesseract
-OCR tessdata
eng
.traineddata OCR识别训练数据文件
新版
Tesseract
-OCR tessdata
eng
.traineddata OCR识别训练数据文件 可自己训练. 1. 样本图片准备 2.
打开
jTessBoxEditor ,选择 Tools -> Merge TIFF,
打开
对话框,选择训练样本所在文件夹,并选中所有要参与训练的样本图片 3 弹出保存对话框,还是选择在当前路径下保存,文件命名为ty.cp.exp6.tif 4.
tesseract
ty.cp.exp6.tif ty.cp.exp6 -l ty batch.nochop makebox 5.
打开
jTessBoxEditor ,点击 Box Editor -> Open ,
打开
步骤2中生成的ty.cp.exp6.tif ,会自动关联到 “ty.cp.exp6.box” 文件: 6. 使用echo命令创建字体特征文件 echo cp 0 0 0 0 0>font_properties. 输入内容 “cp 0 0 0 0 0” 7. 使用
tesseract
生成 ty.cp.exp6.tr 训练文件 在终端中执行以下命名:
tesseract
ty.cp.exp6.tif ty.cp.exp6 nobatch box.train 8. 生成字符集文件 在终端中执行以下命令: unicharset_extractor ty.cp.exp6.box 9. mftraining -F font_properties -U unicharset -O ty.unicharset ty.cp.exp6.tr 与 cntraining ty.cp.exp6.tr 生成之后手工修改 Clustering 过程生成的 4 个文件(inttemp、pffmtable、normproto、shapetable)的名称为 [lang].xxx。这里改为 ty.inttemp、ty.pffmtable、ty.normproto、ty.shapetable。 10. 合并数据文件 在终端中执行以下命令: combine_tessdata ty.
tesseract
b01.jpg result -l ty --psm 7
文字识别
Tesseract
-OCR tessdata
eng
.traineddata OCR识别训练数据文件
1. 样本图片准备 2.
打开
jTessBoxEditor ,选择 Tools -> Merge TIFF,
打开
对话框,选择训练样本所在文件夹,并选中所有要参与训练的样本图片 3 弹出保存对话框,还是选择在当前路径下保存,文件命名为ty.cp.exp6.tif 4.
tesseract
ty.cp.exp6.tif ty.cp.exp6 -l ty batch.nochop makebox 5.
打开
jTessBoxEditor ,点击 Box Editor -> Open ,
打开
步骤2中生成的ty.cp.exp6.tif ,会自动关联到 “ty.cp.exp6.box” 文件: 6. 使用echo命令创建字体特征文件 echo cp 0 0 0 0 0>font_properties. 输入内容 “cp 0 0 0 0 0” 7. 使用
tesseract
生成 ty.cp.exp6.tr 训练文件 在终端中执行以下命名:
tesseract
ty.cp.exp6.tif ty.cp.exp6 nobatch box.train 8. 生成字符集文件 在终端中执行以下命令: unicharset_extractor ty.cp.exp6.box 9. mftraining -F font_properties -U unicharset -O ty.unicharset ty.cp.exp6.tr 与 cntraining ty.cp.exp6.tr 生成之后手工修改 Clustering 过程生成的 4 个文件(inttemp、pffmtable、normproto、shapetable)的名称为 [lang].xxx。这里改为 ty.inttemp、ty.pffmtable、ty.normproto、ty.shapetable。 10. 合并数据文件 在终端中执行以下命令: combine_tessdata ty.
tesseract
b01.jpg result -l ty --psm 7
Android平台上OCR识别应用技术解密
本节课介绍在Android系统平台基于OpenCV与
Tesseract
-OCR框架实现对身份证号码识别技术为例,探讨移动平台上实际项目中OCR识别的常规处理流程与相关算法介绍
【机器视觉】
tesseract
基本使用
1.1
tesseract
1.1.1基础知识 主要用来文字图片的识别,验证码的识别等。就是将图像翻译成文字,也就是文字识别,是由googl公司推出的 安装包下载地址 训练数据集下载地址 使用方式 百度搜索:
tesseract
,下载该软件,安装 设置该软件的环境变量 在含有想要识别的文件中
打开
cmd,使用命令tesserct 图片名.png 文本文件名 如果想要识别中文数据,我们可以通过更改训练数据的包来更改。首先,在
tesseract
中找到目录tessdata,将该数据集中的
eng
.traineddata文件替换成我们从网上下载的训练集,名字要和原来的文件的名字一样。 1.1.2
jTessBoxEditor
jTessBoxEditor是一个用于
Tesseract
OCR的字体编辑器与训练器,可以编辑
Tesseract
2.0x和3.0x格式的字体数据,并全自动完成
Tesseract
训练。它能读取包括多页TIFF在内的常见图像格式,运行该程序需要Java运行环境7或更高版本。 使用jTessBoxEditor生成.box文件的步骤是: 选择Tools -> Merge TIFF,
打开
对话框,选择训练样本所在文件夹,并选中所有要参与训练的样本图片,然后点击
打开
按钮,出现文件保存对话框,输入文件名:num_1.font.exp0.tif,完成后会出现merge完成的提示。
打开
命令提示符,进入步骤1生成的num_1.font.exp0.tif文件所在目录,然后执行命令:
tesseract
num_1.font.exp0.tif num_1.font.exp0 –l
eng
batch.nochop makebox,执行完成后,会在当前目录下生成num_1.font.exp0.box文件。
C#
110,533
社区成员
642,574
社区内容
发帖
与我相关
我的任务
C#
.NET技术 C#
复制链接
扫一扫
分享
社区描述
.NET技术 C#
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
让您成为最强悍的C#开发者
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



